新手,在控制台输入python manage.py makemigrations报错:
'utf-8' codec can't decode byte 0xb2 in position 0:invalid start byte。
计算机名称也是英文,问题到底出在哪啊。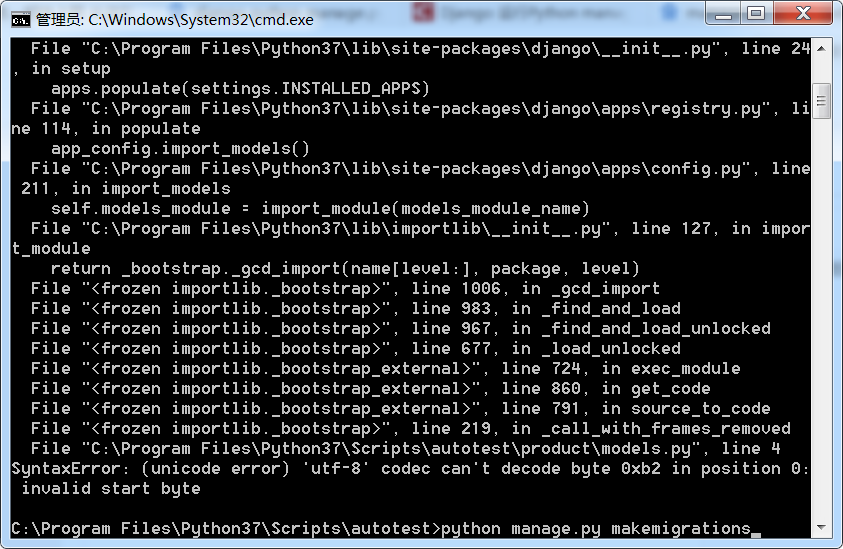
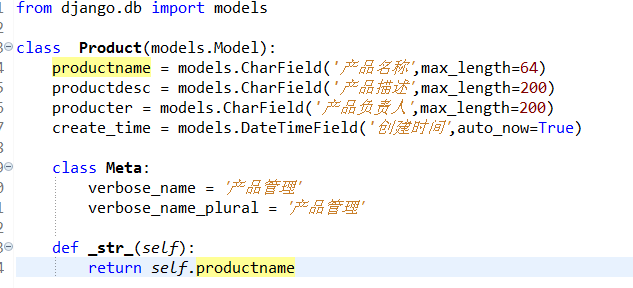
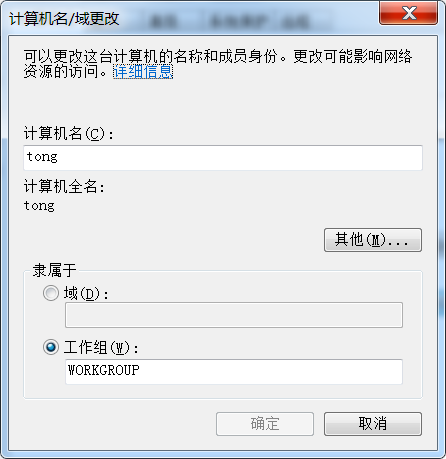

'utf-8' codec can't decode byte 0xb2 in position 0:invalid start byte

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
 threenewbee 2020-03-02 14:30关注
threenewbee 2020-03-02 14:30关注开头加上 # encoding: utf-8 或者 import sys sys.setdefaultencoding('utf-8') 并且保存你的py文件的时候选择urf8编码本回答被题主选为最佳回答 , 对您是否有帮助呢?评论 打赏解决 2无用 9举报 分享
- 2024-09-23 21:51求求给个学位吧的博客 对于由excel导出的csv文件,一般编码为ANSI编码,而非utf-8编码。需要用“记事本”打开csv文件,查看其实际编码格式,之后在上面的语句中添加encoding='编码格式',即可正确读取csv文件。因为这条语句默认按照utf-8...
- 2020-12-21 18:55本文将深入探讨“utf8 codec can’t decode byte 0xc0 in position 0: invalid start byte”这一错误,以及如何针对Zenmap工具提供部分解决方案。 首先,让我们了解这个错误的含义。UTF-8是一种广泛使用的字符编码...
- 高级数据分析师的博客 这个报错表示在尝试使用 UTF-8 解码方式读取文件时出现了问题,很可能是因为文件中包含了不被 UTF-8 编码所支持的字符。可以尝试使用其他编码方式读取文件,如使用 encoding=‘gbk’ 参数来指定文件编码为 GBK 编码...
- 2023-05-05 22:28爱编程的喵喵的博客 本文主要介绍了爬虫编码UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xb1 in position 78: invalid start byte解决方案,希望能对学习python的同学们有所帮助。 文章目录 1. 问题描述 2. 解决方案
- 2024-06-11 19:12KAWS ?的博客 发现这里的name读的是我的电脑名称,也就是主机名,回到设置,把电脑名称改成英文就好了,再次回到pycharm执行pip python manage.py runserver,浏览器。问题显示在socket.py的hostname, aliases, ipaddrs = ...
- 2023-08-27 22:22zyd的小飞船的博客 是由于设置了decode()方法的第二个参数errors为严格(strict)形式造成的,因为默认就是这个参数,将其更改为ignore即可。1.单独配置yolov7 pose 的环境。
- 2024-03-27 17:59星河欲转。的博客 UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb7 in position 36: invalid start byte
- 2024-04-30 12:09嵌入式拳铁编曲MikeZhou的博客 【Python】解决Socket库BUG编码报错问题(UnicodeDecodeError: utf-8 codec can t decode byte 0xb3 in position 0: invalid start byte)
- 2020-05-25 13:58小步积的博客 read_csv报错,报错信息如题,解决: df = pd.read_csv(filename, encoding='gb18030')
- 2024-07-26 16:39
 文件编码检测-Python解决UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xb7 in position 0: invalid startkaka_R-Py的博客 文件编码检测-Python解决UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb7 in position 0: invalid start
文件编码检测-Python解决UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xb7 in position 0: invalid startkaka_R-Py的博客 文件编码检测-Python解决UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb7 in position 0: invalid start - 今夕是何年,的博客 找到路径:E:\All_in\新建文件夹\yolo project\pyqt 5.0\PyQt5-YOLOv5-yolov5_v5.0\utils\。这个报错通常是由于文件编码问题引起的。可能是因为文件的编码格式不是 UTF-8 导致的。
- 2023-03-23 21:01路西girl的博客 UnicodeDecodeError: utf-8 codec can t decode byte 0x8b in position 1: invalid start byte
- BigBaimatou的博客 这通常是因为在尝试读取或处理文件时,Python 尝试以 UTF-8 编码解码数据,但文件的实际编码格式与 UTF-8 不兼容。有些 UTF 编码格式(如 UTF-8 和 UTF-16)在文件开始时会包含一个 BOM(字节顺序标记),这会干扰...
- 2023-12-11 15:05时雨空晴的博客 使用msgpack.Unpacker对bin文件进行解包时,出现错误:'utf-8' codec can't decode byte 0xb0 in position 0: invalid start byte。默认情况下,解包程序参数raw=False,它假设str类型是有效的UTF-8字符串。
- 2022-07-22 16:51Cloudia8020的博客 UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb2 in position 0: invalid start byte
- 2025-04-28 09:49一枚努力的程序猿的博客 写个一个复杂的界面处理程序,代码太长,将其分解为模块化代码,结果怎么编译都错误,显示编码格式的问题,怎么修改都不行,后续用Notepad++查看文件的信息属性,发现显示是utf-8;折腾了半天,终于找到解决办法。...
- 2023-04-23 21:14胖胖的小龙猫的博客 报错:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb0 in position 2: invalid start byte,pd.read_csv报错解决方案
- 2024-08-24 10:58baijuyushishiren的博客 encoding='utf-8-sig改成gbk ,改成gb2312都不行的时候,可以考虑是不是你的csv编码出问题了.格式不对,那么可以思考把excel存为csv时改成以utf-8的方式存储,当然前提是你要Excel为2016版以上。
- wbp小鬼的博客 UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb9 in position 0:invalid start byte
- 没有解决我的问题, 去提问
