
技术讨论帖(因作者没钱所以没悬赏,抱歉)
#代码
data_DNA = input('请输入要处理的DNA序列')
data_print_1 = data_DNA.count('GA')
print('所输入的DNA序列中有 ' + str(data_print_1) + ' 个 GA')
data_print_2 = data_DNA.find('GA') + 1
print('第一个GA出现在DNA序列的第' + str(data_print_2) + '位')
print('''所有 GA 出现的位置分别为''')
i = 1
subscript_data = [0,len(data_DNA)]
data_print_3_1 = []
data_print_3_2 = []
while i <= data_print_1:
subscript_data_1 = data_DNA.find('GA',subscript_data[0])
subscript_data[0] = subscript_data_1 + 1
subscript_data_2 = data_DNA.rfind('GA',0,subscript_data[1] + 1)
subscript_data[1] = subscript_data_2 - 1
data_print_3_1.append(subscript_data_1)
data_print_3_2.append(subscript_data_2)
i += 1
print('从前往后数:')
counter = 1
for i in data_print_3_1:
print('第%d个 GA 在序列第 %d 位'%(counter,i+1))
counter += 1
print('从后往前数')
counter = 1
for i in data_print_3_2:
print('第%d个 GA 在序列第 %d 位的'%(counter,i+1))
counter += 1
问题:
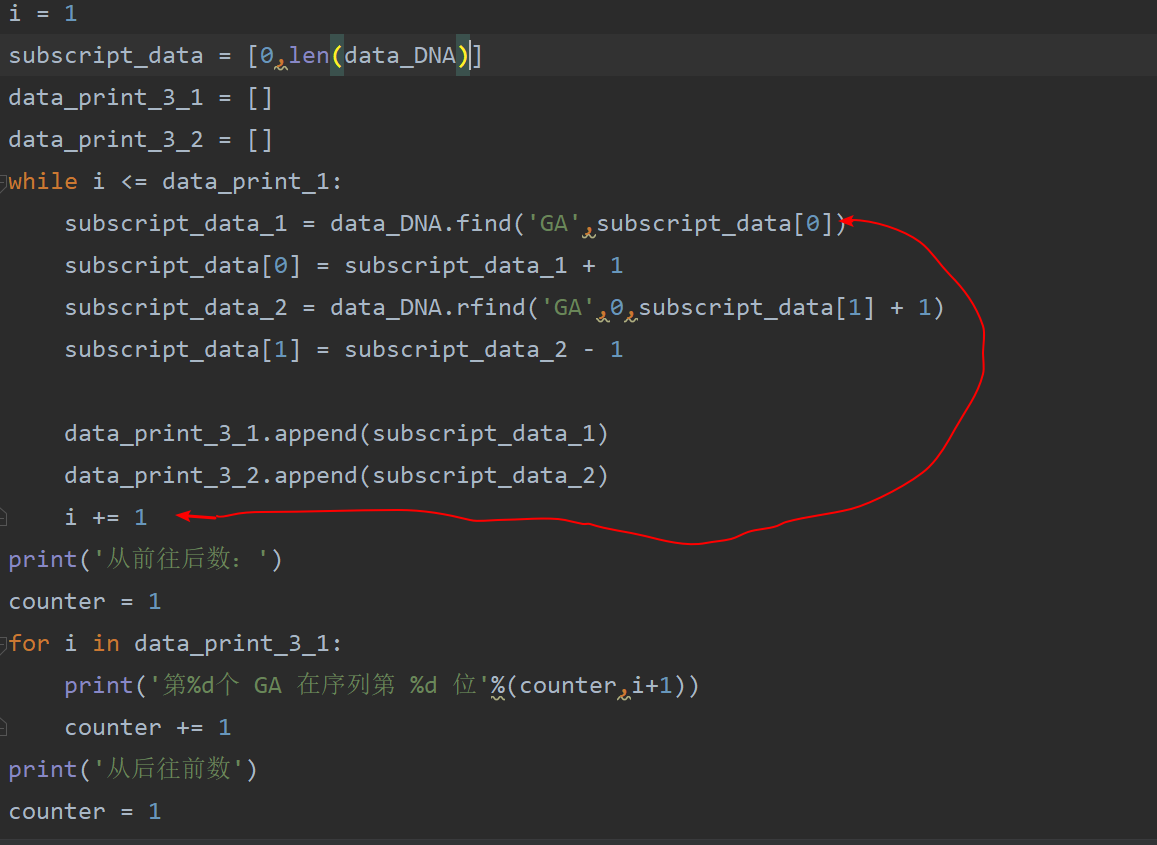
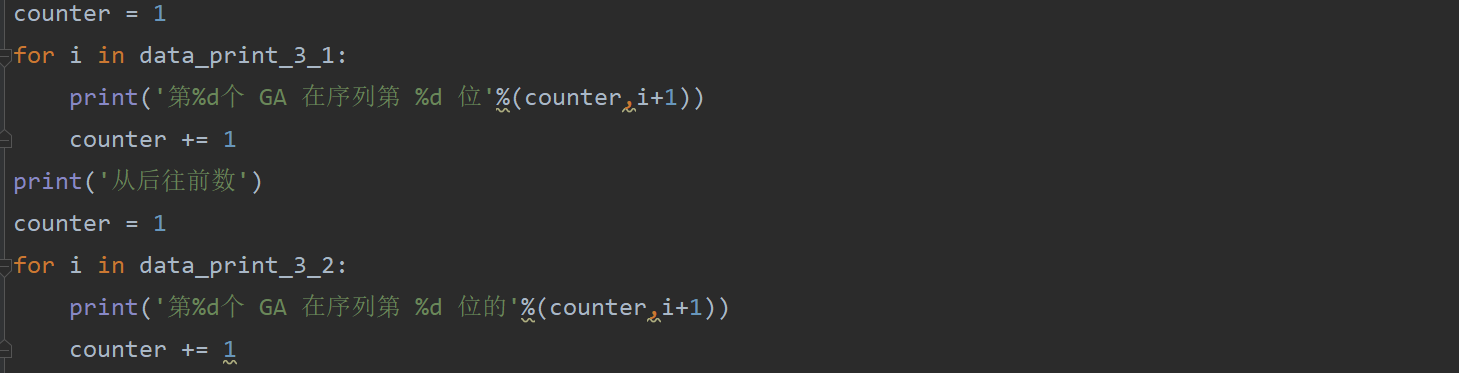
这两部分看着就头疼就真的不能有简化的余地吗???
##要达到的目的: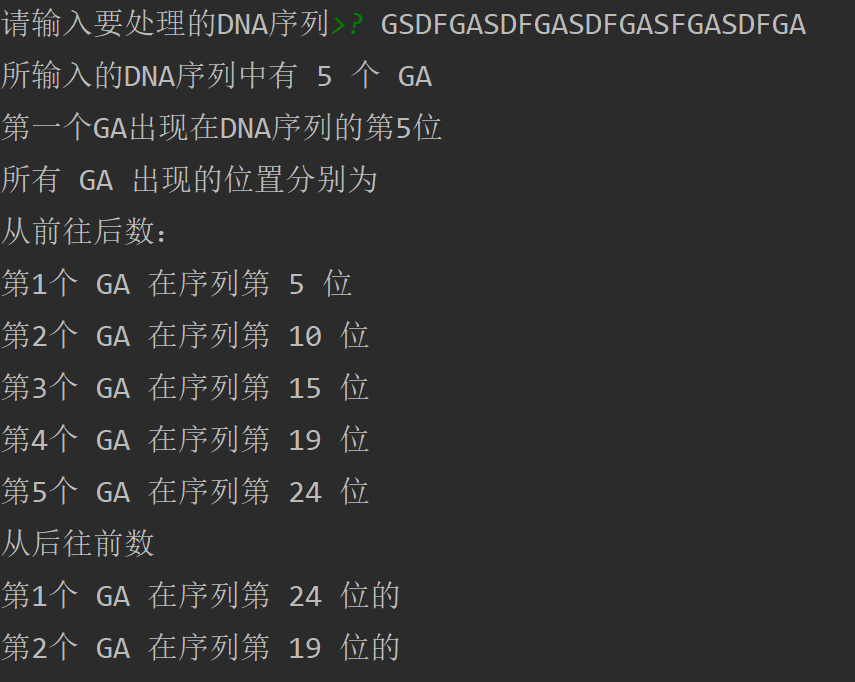

#结语
好了就这个案例
想交流的咱们 私聊




