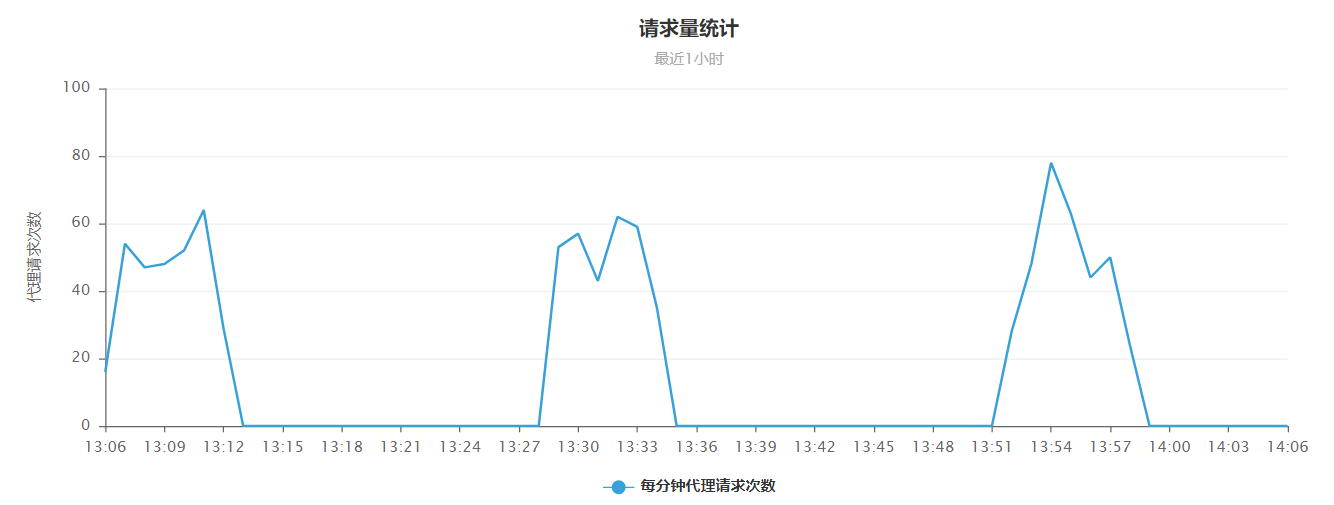
scrapy执行的时候,在CMD窗口观察到执行程序总是总是总是会停一段时间(我在一些步骤设置了print所以能看到大概执行情况),因为设置了log级别,在CMD窗口也看不到程序时时刻刻在干啥,pycharm打开setting文件注释了log级别设置,实际上好像也没有生效,然后通过ip代理网站对ip使用情况的检测记录,看到请求也是不连续的,这个太影响效率了,是哪儿没整对吗。

scrapy执行的时候,在CMD窗口观察到执行程序总是总是总是会停一段时间(我在一些步骤设置了print所以能看到大概执行情况),因为设置了log级别,在CMD窗口也看不到程序时时刻刻在干啥,pycharm打开setting文件注释了log级别设置,实际上好像也没有生效,然后通过ip代理网站对ip使用情况的检测记录,看到请求也是不连续的,这个太影响效率了,是哪儿没整对吗。
 分享
分享





