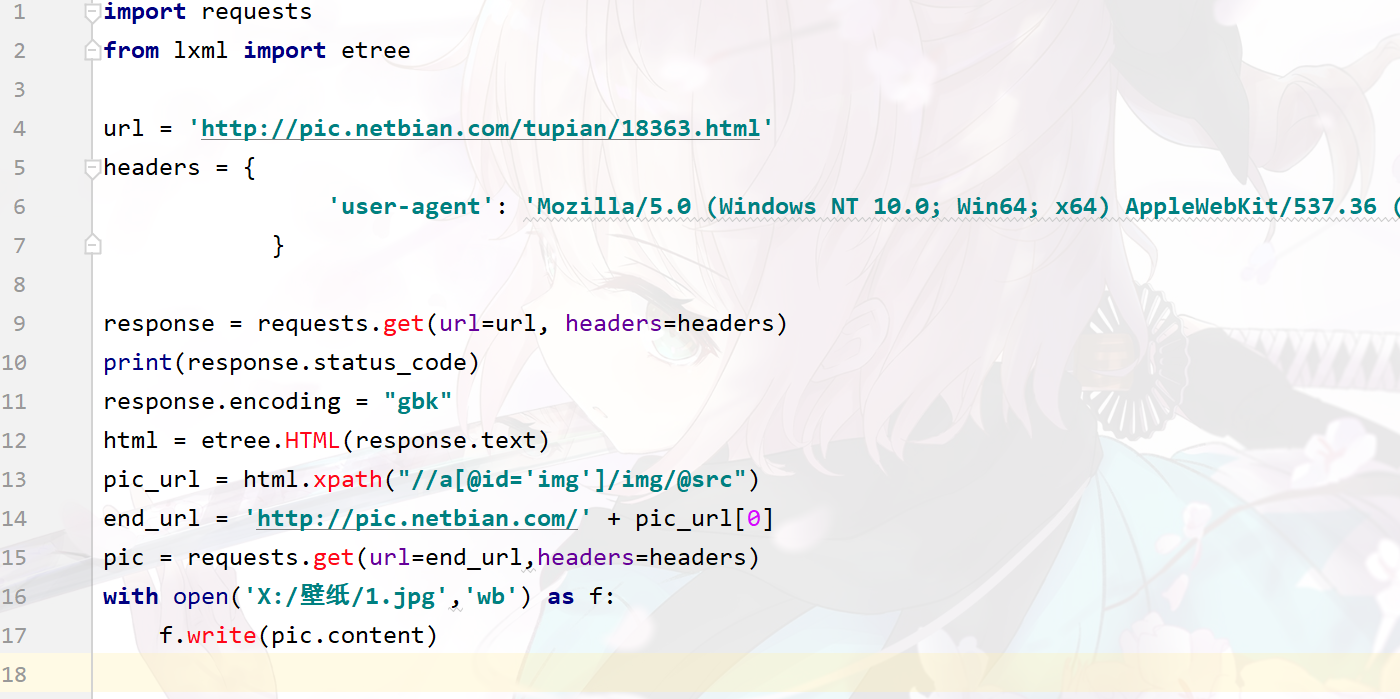
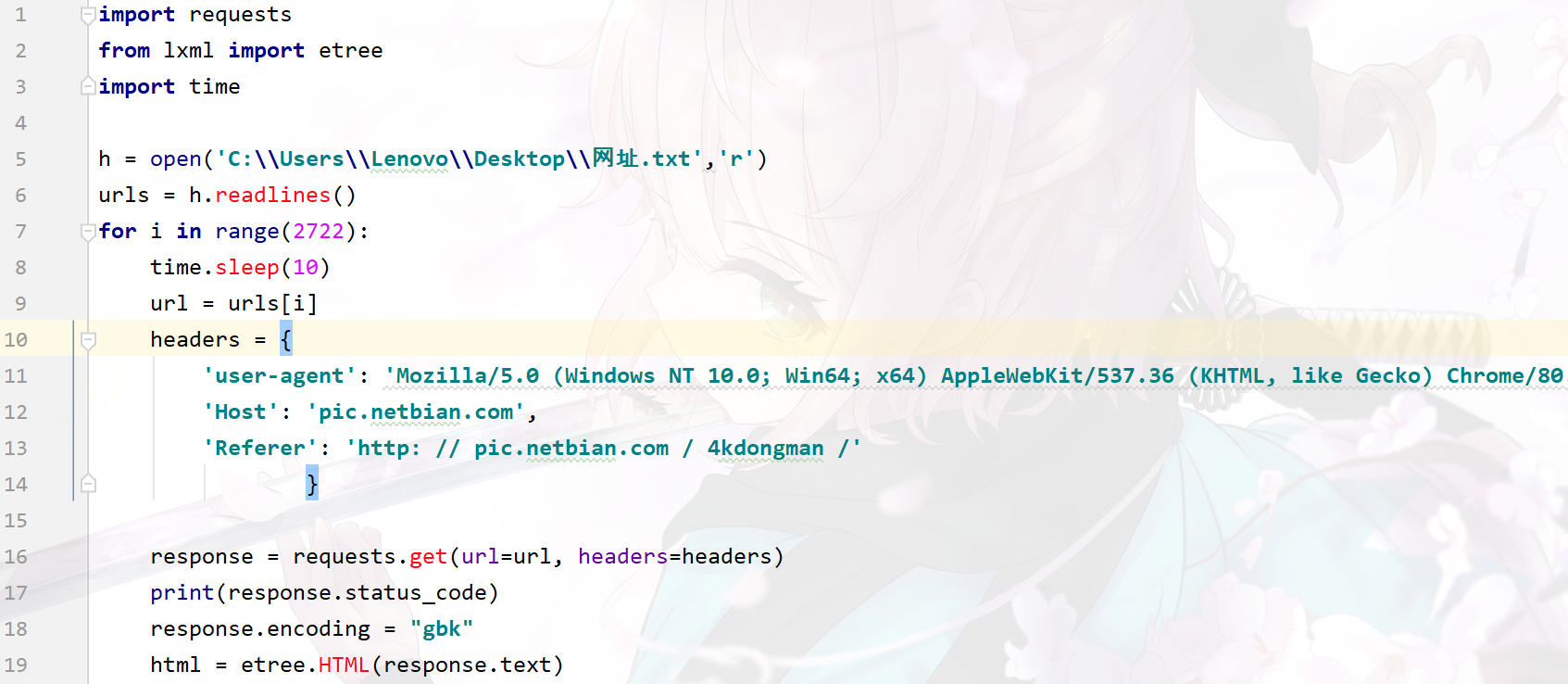
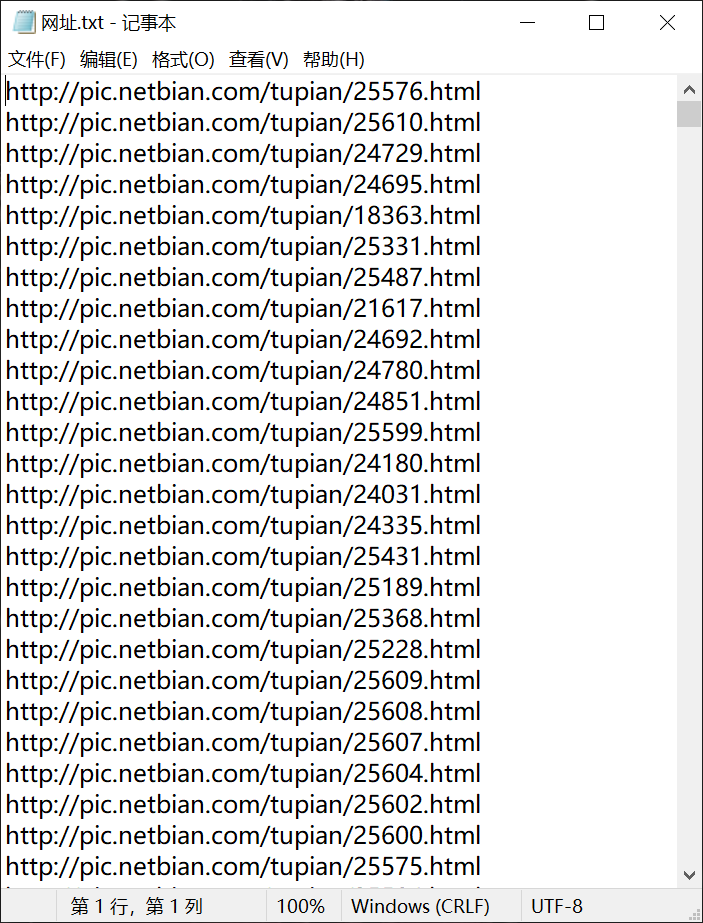
第一张图我是把txt文件中第一个网址拿出来,然后保存图片成功,但是当我读取txt文件,准备开始批量爬取的时候(图二),状态码为404,单独爬取一个网站的时候没问题,一放在多个网站中就报错,怎么办?

第一张图我是把txt文件中第一个网址拿出来,然后保存图片成功,但是当我读取txt文件,准备开始批量爬取的时候(图二),状态码为404,单独爬取一个网站的时候没问题,一放在多个网站中就报错,怎么办?
 分享
分享
你读取的时候会在每个链接末尾添加换行符\n,所以请求url的时候就会因为末尾有换行符导致失败
['https://456\n', 'https://123']
就像这样
读取的时候要加一条
for url in urls:
print(url.replace('\n',''))
把换行符去掉就没问题了
分享

