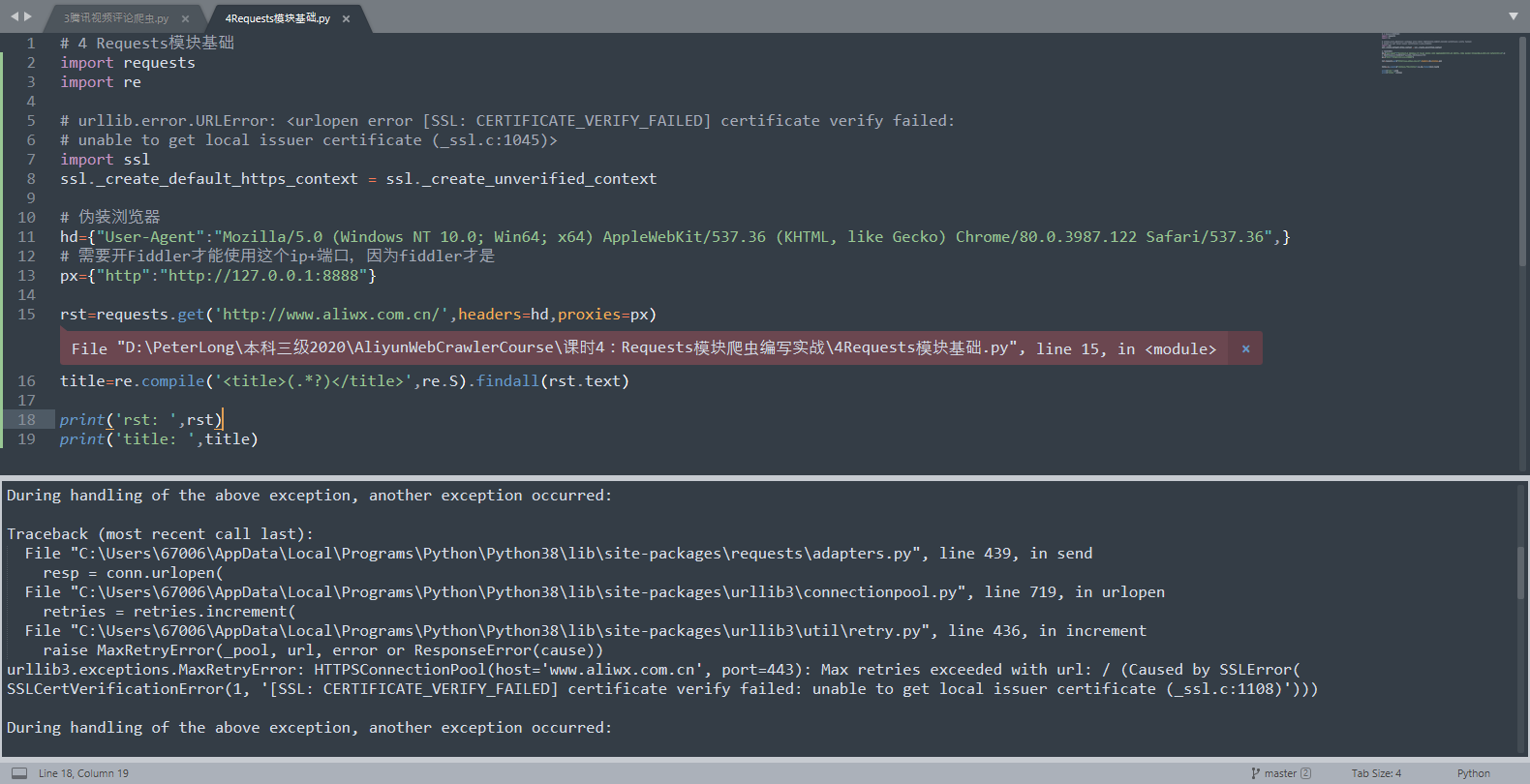
requests库爬虫报错import ssl也没用
ssl.SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1108)
代码
import requests
import re
# urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed:
# unable to get local issuer certificate (_ssl.c:1045)>
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
# 伪装浏览器
hd={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36",}
# 需要开Fiddler才能使用这个ip+端口
px={"http":"http://127.0.0.1:8888"}
rst=requests.get('http://www.aliwx.com.cn/',headers=hd,proxies=px)
title=re.compile('<title>(.*?)</title>',re.S).findall(rst.text)
print('rst: ',rst)
print('title: ',title)
详细说明:在看阿里云的爬虫课程实操时出现这个问题,我试过了这个取消全局验证的方法但是仍旧没用,提示信息就是这样,猜测是我的ip和端口有问题?但是之前的操作都和老师是一样的,有大佬知悉请指教一下