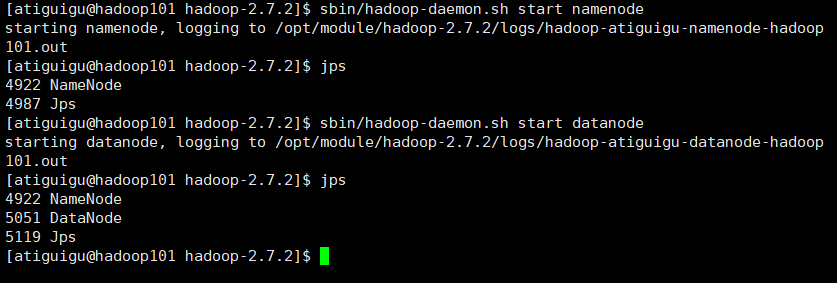
学习hadoop的时候,启动hadoop伪分布式集群的时候,启动过程是正常的,没有报错。jps查看也是显示正常运行。namenode的name目录是正常的。但是在/opt/module/hadoop-2.7.2/data/tmp/dfs/data目录(datanode的目录)下没有内容。
namenode和datanode是启动了的。
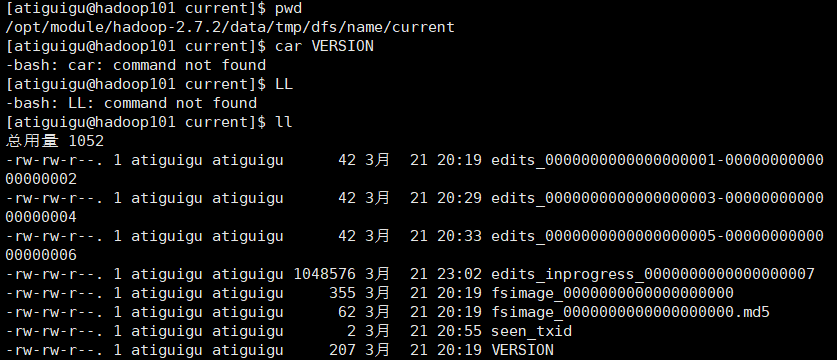
namenode的name文件夹下内容也是正常的
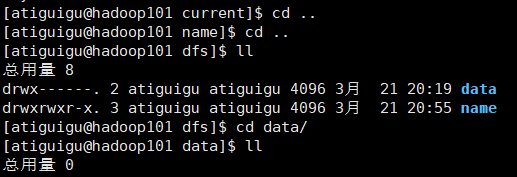
datanode的data文件夹下空白,不应该是显示VERSION等信息吗?

学习hadoop的时候,启动hadoop伪分布式集群的时候,启动过程是正常的,没有报错。jps查看也是显示正常运行。namenode的name目录是正常的。但是在/opt/module/hadoop-2.7.2/data/tmp/dfs/data目录(datanode的目录)下没有内容。
namenode和datanode是启动了的。
namenode的name文件夹下内容也是正常的
datanode的data文件夹下空白,不应该是显示VERSION等信息吗?
 分享
分享
我也是!不过我datanode jps只显示过一次 用master ssh登录节点运行datanode的时候dfs data下面也空空一片 应该是权限出问题 但是完全没有办法
分享

