
#统计数据画饼图
plt.sca(ax_industryRate)
industries = ct_excel.industryName
# dic=ct_excel['industryName'].value_counts() #获得个数之后怎么画饼图?
dic = {} # 采用数据字典统计企业所处行业情况
for item in industries:
if item in dic.keys():
dic[item]+=1
else:
dic[item]=1
a=[]
b=[]
c=0
for key in dic:
if dic[key] >= 3: #3家以下企业的行业都算作其他
a.append(key)
b.append(dic[key])
else:
c += dic[key]
a.append("其他")
b.append(c)
size=[]
t=sum(b)
label = a
for u in b:
i=u/t
size.append(i)
plt.plot(size)
plt.pie(size,labels=label,autopct='%1.lf%%')
plt.show()
从网上搜到的一个比较麻烦的办法,先统计industryName每种出现了几次
出现次数小于三次的都算作其他
然后画饼图,但出来的结果很奇怪,莫名其妙多一条线
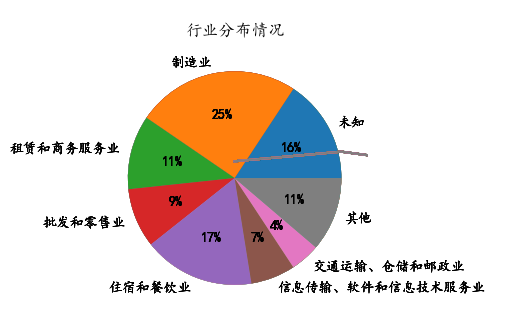
求大神指导下怎么去掉这条线?
网上还看到一个value_counts()方法,结果是能拿到的,每个种类出现的次数,
但后面如何合并出现频率低的种类,如何画饼图,没有找到资料。
希望有人不吝赐教




