
本人小白,准备爬取豆瓣top250电影榜单的时候,发现request回来的数据中排名1~8的电影数据没有,不知是设置问题还是代码问题,恳请大佬指正,代码及结果如图_
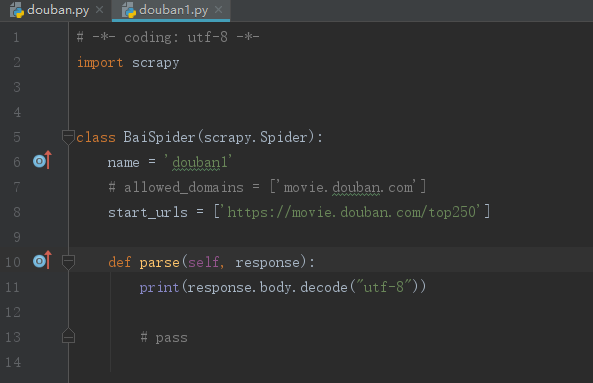
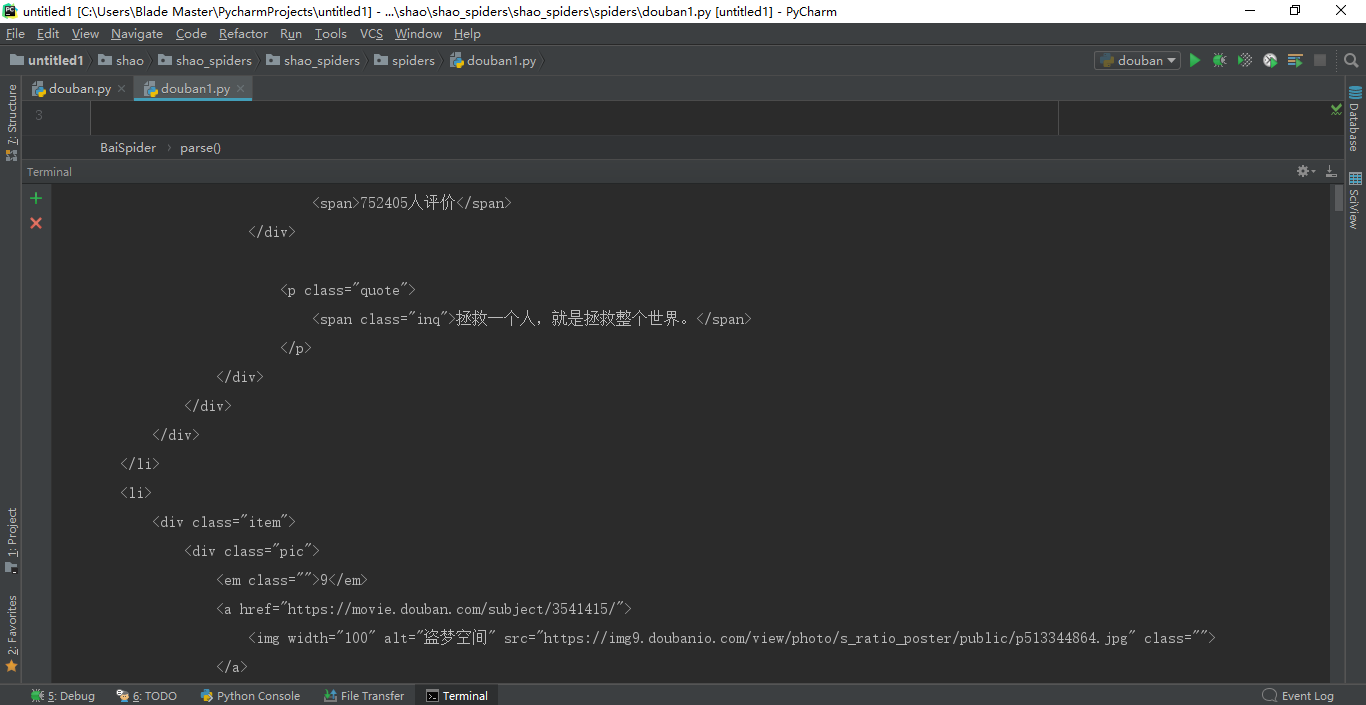
感谢回答,问题已经解答:数据其实已经返回,但只是没有显示,也许是数据太多的问题,只是有点难受,但不影响之后的提取操作,如利用xpath进行提取
**class Douban1Spider(scrapy.Spider):
name = 'douban1'
allowed_domains = ['https://movie.douban.com/top250']
start_urls = ['https://movie.douban.com/top250/']
def parse(self, response):
node_list = response.xpath("//div[@class='info']")
filmname = node_list.xpath("./div/a/span[1]/text()").extract()[0]
print(filmname)**
**返回了之前出现不了《肖申克的救赎》的电影名。
**再次感谢。







