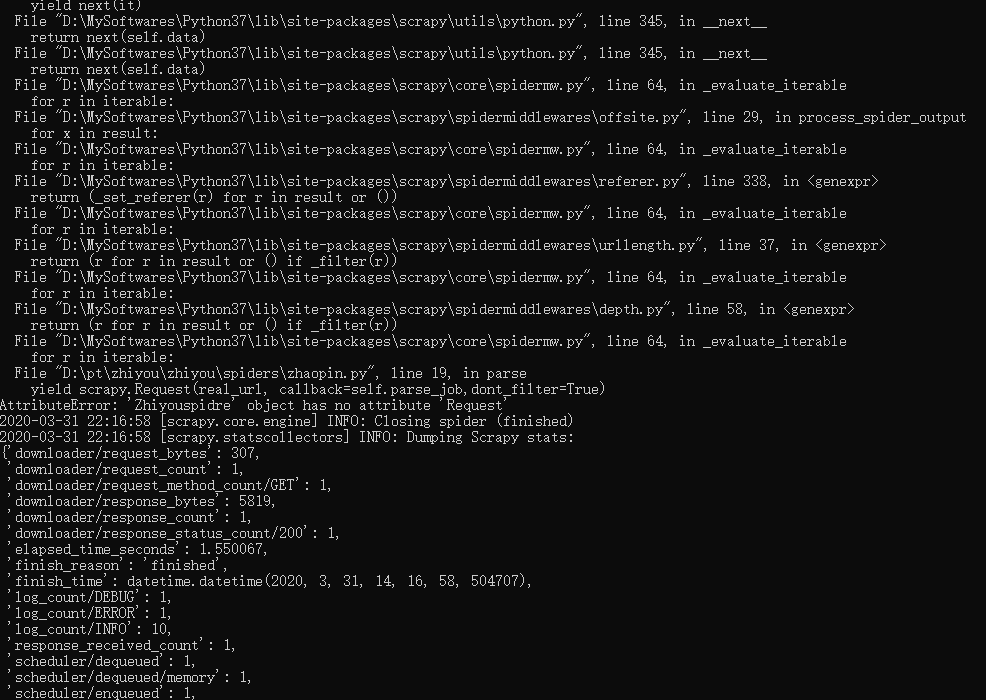
import scrapy
from bs4 import BeautifulSoup
import sys
sys.path.append("../")
from items import ZhiyouItem
class Zhiyouspidre(scrapy.Spider):
name = "zhiyou"
allowed_domains = ["jobui.com/"]
start_urls = ["https://www.jobui.com/rank/company/"]
def parse(scrapy,response):
bs = BeautifulSoup(response.text,"html.parser")
datas = bs.find(class_="textList flsty cfix").find_all("a")
for data in datas:
real_url = "https://www.jobui.com/rank{}jobs".format(data["href"])
yield scrapy.Request(real_url, callback=self.parse_job,dont_filter=True)
def parse_job(self,response):
bs = BrautifulSoup(response.text,"html.parser")
print(bs)