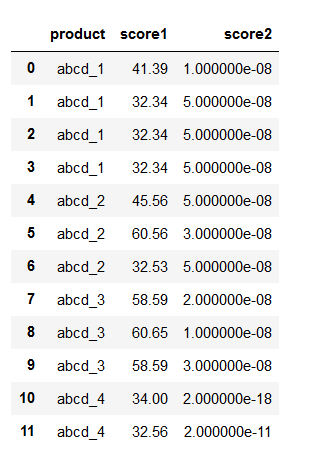
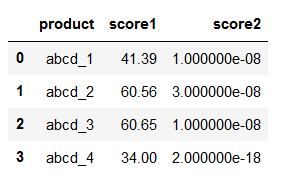
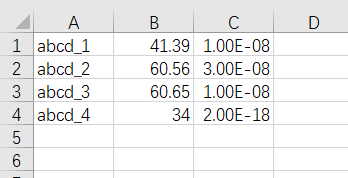
有这样一个excel文件
abcd_1 41.39 1.00E-08
abcd_1 32.34 5.00E-08
abcd_1 32.34 5.00E-08
abcd_1 32.34 5.00E-08
abcd_2 45.56 5.00E-08
abcd_2 60.56 3.00E-08
abcd_2 32.53 5.00E-08
abcd_3 58.59 2.00E-08
abcd_3 60.65 1.00E-08
abcd_3 58.59 3.00E-08
abcd_4 34.00 2.00E-18
abcd_4 32.56 2.00E-11
第一列代表不同产品,(比如表中列的四个产品abcd_1,abcd_2,abcd_3,abcd_4),因为来自于不同仓库(数据中没用,就没有在表里列出来),所以名字会有相同。第2列代表评分1,该评分越高越好,第3列代表评分2,该评分越低越好。要根据这两个评分,找到每个产品下评分最优的那一行值,并输出为新的excel。
求问大神,python怎么根据产品名称分组,然后组内排序找到最好的一个,然后把每个产品最好的一个的那一行数据输出到新文件中呢?