python结果与wordCrtl+F搜索结果不一致。代码如下:
python结果:

word搜索结果:
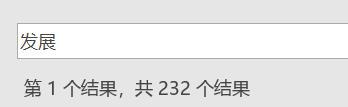
显然“发展”这一词语出现的频次是不同的,请问是哪里的问题?如何改进?谢谢!!!

python结果与wordCrtl+F搜索结果不一致。代码如下:
python结果:
word搜索结果:
显然“发展”这一词语出现的频次是不同的,请问是哪里的问题?如何改进?谢谢!!!
 分享
分享
以下回答参考 皆我百晓生、券券喵儿 等免费微信小程序相关内容作答,并由本人整理回复。
在你的Python代码中,你使用了jieba.cut()函数来进行中文分词,并将结果存储在一个列表中。然后,你使用一个字典counts来统计每个词的出现次数。
然而,在items.sort()方法之后,你并没有对这个排序后的列表应用任何额外的操作。如果你想要按照单词出现的频率降序排列,你应该首先对这个排序后的列表应用items.sort(key=lambda x: x[1]),然后再打印出这些单词及其频率。
以下是修改后的代码:
import jieba
# 加载文本文件
with open('十九大报告(无空格版).txt', 'r', encoding='utf-8') as f:
txt = f.read()
# 使用jieba进行分词
words = jieba.lcut(txt)
# 创建一个字典来统计每个词的出现次数
counts = {}
for word in words:
if word not in counts:
counts[word] = 1
else:
counts[word] += 1
# 按照词频降序排序
sorted_counts = sorted(counts.items(), key=lambda x: x[1], reverse=True)
# 打印前100个单词及其频率
for i in range(100):
word, freq = sorted_counts[i]
print(f"{word:<10} {freq:>5}")
这段代码应该能够解决你的问题。现在,它会按照单词出现的频率降序排列并打印出前100个单词及其频率。
分享


