
创建表:
CREATE TABLE `message` (
`send_id` int(11) DEFAULT NULL COMMENT '发送者id',
`accept_id` int(11) DEFAULT NULL COMMENT '接受者id',
`message` varchar(255) DEFAULT NULL COMMENT '消息详情',
KEY `SEND_ID` (`send_id`),
KEY `ACCEPT_ID` (`accept_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='聊天记录';
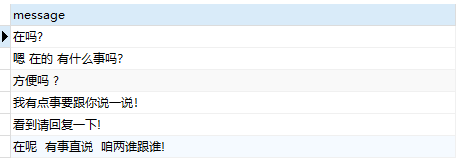
查询某人跟某人之间的聊天记录:
SELECT message FROM `message` where send_id in (1,2) and accept_id in (1,2)
但是这样就用不到索引了,聊天记录的数据量多,一多就查询起来就慢了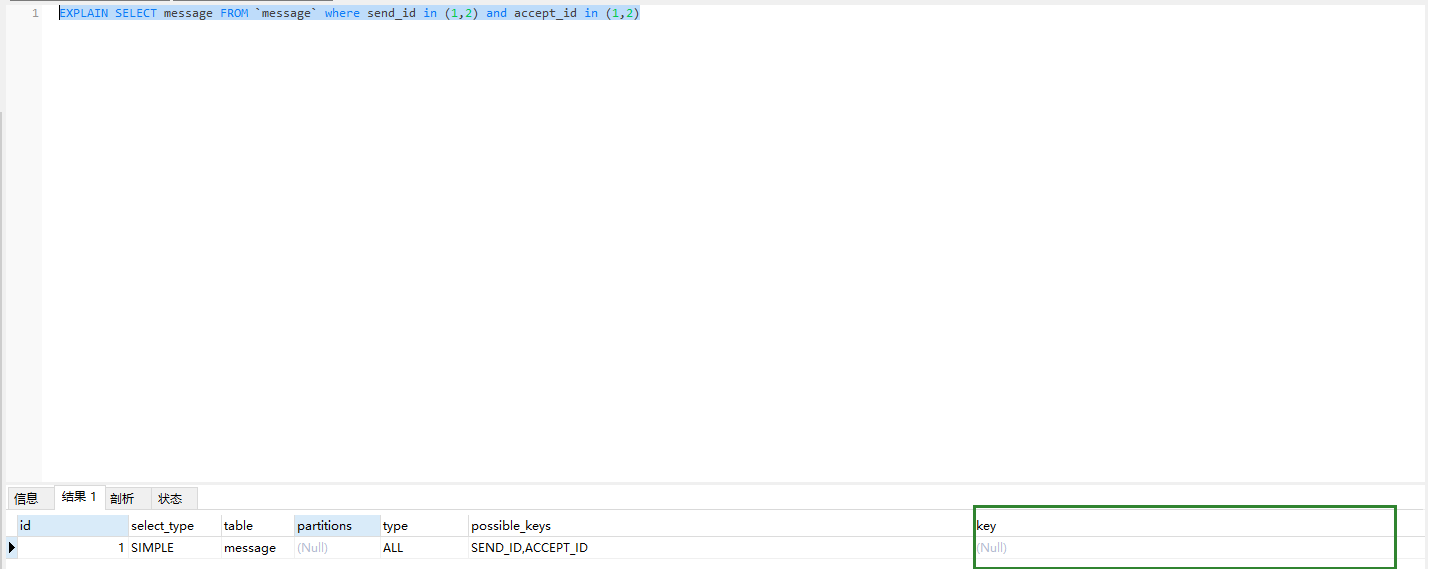
各位有什么好的建议吗?
我有一个奇怪的想法,假设用户A的id为1,用户B的id为2,保存到消息表里面的id(非唯一,小的id放前面,大的id放后面)就是12,形成了点对点聊天记录的唯一性,这样查最后一条聊天记录也方便,也不知道这样行不行的通,以前从未接触过这东西 ,以前就觉得架构师之类的牛逼,现在才发现架构师的牛逼是我想象不到的





