import requests
import json
if __name__ == "__main__":
url = 'https://movie.douban.com/j/search_subjects' # 指定URL
params = {
'type':'movie', 'tag':'%E5%96%9C%E5%89%A7','sort':'recommend', 'page_limit':'20',
'page_start':'0'
}
headers = {
'User Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36'
} # UA伪装
response = requests.get(url=url, params=params, headers=headers) # get请求
# 获取响应数据
list_data = response.json()
fp = open('./douban.json', 'w', encoding='utf-8')
json.dump(list_data, fp=fp, ensure_ascii=False)
print('保存成功!!!')

做了python爬取豆瓣电影程序,但是一直出错

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新

 关注
关注我也爬过豆瓣,应该是你直接用 response.json 这个用法不对,应该将 response.text 转成 JSON:
import requests import json url="https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&page_limit=50&page_start=0" headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36", "Referer":"https://movie.douban.com/" } response = requests.get(url,headers=headers) # loads as json result = json.loads(response.text) # get subjects subjects = result['subjects'] def itemInfo(item): info = '{},{},{},{}\r\n'.format(item['title'], item['rate'],item['url'],item['cover_x']) return info # write to file f1 = open('E:/film.log','w',encoding='utf-8') for item in subjects: print(itemInfo(item)) f1.write(itemInfo(item))结果:
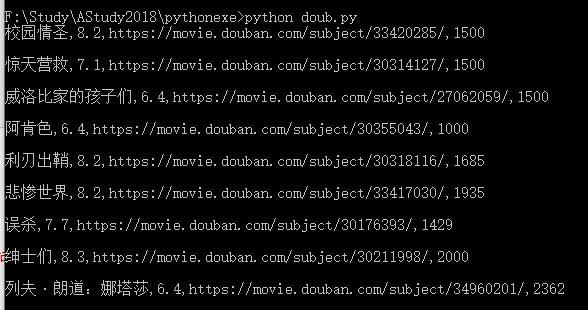 本回答被题主选为最佳回答 , 对您是否有帮助呢?解决评论 打赏无用 1举报 分享
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决评论 打赏无用 1举报 分享
- 2024-08-04 17:55左手の明天的博客 豆瓣是一个电影资讯网站,用户可以在网站上查找电影信息、评论电影等。我们希望通过爬虫程序获取豆瓣电影的名称、评分和简介等信息,以便进行数据分析或制作推荐系统。
- 2020-11-27 18:10weixin_39528525的博客 前言:在掌握一些基础的爬虫...准备环境:Pycharm、python3、爬虫库request、xpath模块、lxml模块第一步:分析url ,理清思路先搜索豆瓣电影top250,打开网站可以发现要爬取的数据不止存在单独的一页,而是存在十页当...
- 2025-06-05 13:56小尤笔记的博客 豆瓣TOP250电影是一个经典的电影排行榜,下面我将详细讲解如何使用Python编写爬虫来获取这些数据。我们将使用requests库发送HTTP请求,库解析HTML内容,以及pandas库存储和保存数据。
- 2020-12-28 19:46海盐冰梨的博客 想了几天,决定了要尽快给老师说自己的想法和方向,做什么还是靠自己比较靠谱。身边的同学这学期都开始去实习了,自己投了很多份简历,大都石沉大海,唯一收到面试通知的广发基金,结果因为表现太差,缺乏深入思考gg...
- 2024-11-17 19:39apwangzitong的博客 BeautifulSoup 是一个 Python 包,功能包括解析 HTML 和 XML 文档、修复含有未闭合标签等错误的文档。这个扩展包为待解析的页面建立一棵树,以便提取其中的数据。...目前,BeautifulSoup常...1. 明确爬取目标及信息结构。
- 2025-06-23 09:48白话说数的博客 上篇文章我们介绍了Pthon爬虫的基本流程,这篇文章我们以豆瓣电影 Top250 为实战对象,从网页结构分析、爬虫代码编写、数据结果存储三个方面来展开,带你揭开网络数据抓取的神秘面纱。
- 2020-12-18 03:44weixin_39610807的博客 本文仅限技术研究与讨论,严禁用于...后面要做作业答辩,改为存储到mysql数据库中代码实现和网上大部分爬取的文章不同,我想要的是每部电影的剧情简介信息所以需要先获取每部电影的链接,再单独爬取每部电影全部代...
- 2021-02-05 06:29weixin_39915694的博客 回家很久了,实在熬不住,想起来爬点数据玩一玩,之前自己笔记本是win7加...然后就还是在win7下开始写代码了(电脑太卡,一直不想装Python),今天爬的是豆瓣音乐top250,比较简单,主要是练练手。代码importrequests...
- 2019-03-01 20:47码猿手的博客 本文旨在提供爬取豆瓣电影《我不是药神》评论和词云展示的代码样例 1、分析URL 2、爬取前10页评论 3、进行词云展示 1、分析URL 我不是药神 短评 第一页url ...amp;limit=20&...sort=new_score&...
- 2021-11-07 09:59YunMo_SixYear的博客 0.第一个403报错,最开始程序出错后,不停的测试问题,然后被豆瓣查,然后查过多种方法,第一种+cookie信息,第二种用代理ip数据池(目前还没学到) 第一种方法如下403报错信息 1.提示逗号报错。排查半天发现是sql...
- 没有解决我的问题, 去提问
