在使用scaler.inverse_transform(y_test)进行反归一化时,报错ValueError: operands could not be broadcast together with shapes (984,2) (4,)(984,2),我断调试了一下,在这个位置报错: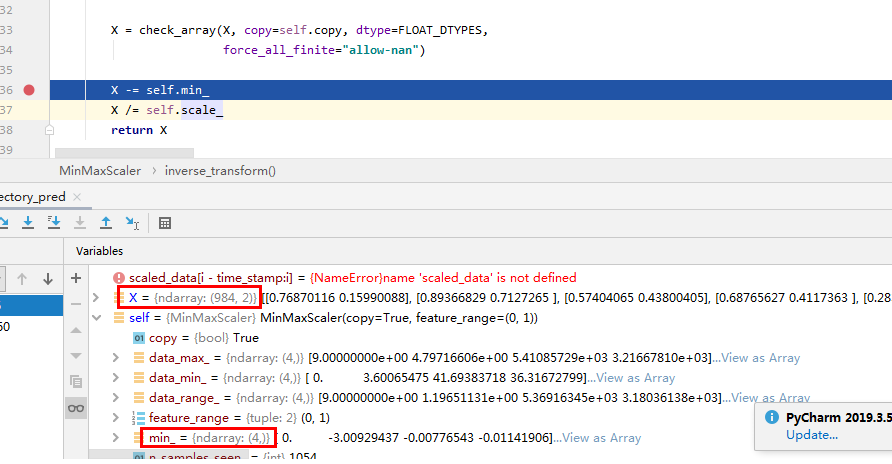

反归一化时报错ValueError: operands could not be broadcast together with shapes

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


6条回答 默认 最新
 Xhen911 2021-09-02 16:14关注
Xhen911 2021-09-02 16:14关注反归一化时,需要和原来归一化时所用的数据有相同的shape。
根据ValueError可知,题主反归一化所用的数据只有2列,而之前做归一化时应该是用了4列的数据。
需要做一些变形,或是拼接,保持相同维数就行了。评论 打赏解决 6无用 3举报 分享
- 2022-03-24 21:21回答 2 已采纳 我使用你的代码,不会报错啊 是不是你的原始数据中有空数据或者不是你写的格式的数据啊
- 2022-02-16 12:30
 python 用pip 安装有的模块时出现报错信息 :ValueError: source code string cannot contain null bytes
python
后端
开发语言
有问必答
回答 5 已采纳 远程看看
python 用pip 安装有的模块时出现报错信息 :ValueError: source code string cannot contain null bytes
python
后端
开发语言
有问必答
回答 5 已采纳 远程看看 - 2021-12-12 15:13回答 3 已采纳 那三组数据 , 大概样子贴一下, 看提示,就是你有个日期字段(字符串类型), 你按数值来要求 plt 展示了。
- 来知晓的博客 问题解决 进阶举例 参考资料 问题描述 在做矩阵数据的归一化处理时,遇到个报错:ValueError: operands could not be broadcast together with shapes (2,32) (2,) 。 源码片段如下: def normalization(X, set_axis...
- 2022-04-05 22:02 python需要根据列表元素整数大小进行排序,遇到列表元素内有字母报错ValueError: invalid literal for int() with base 10: 'Amos'
python
回答 1 已采纳 txts.sort(key=lambda x:int(x[3]),reverse = True)
- 2022-08-24 17:04回答 3 已采纳 既然手动输入可以,那就用动态函数: from sympy import * #用于函数定义求导 from scipy.optimize import fsolve #用于方程求解 x=
- 2019-10-09 16:07回答 1 已采纳 np.random.randint(low,high)中,出现这种错误即你的total_fault_buses取值为0,你的low=high=0就会报错了!
- 2017-10-11 20:14nana-li的博客 ValueError: operands could not be broadcast together with shapes (100,3) (3,1) 解释: 本人出现的问题是,dataMatrix,weights的大小分别为(100,3) (3,1), 是‘list‘>、类型,而不是类型,直接进行...
- 2021-11-15 18:00回答 1 已采纳 在pymongo.MongoClient函数里加个参数ssl_cert_reqs=ssl.CERT_NONE,试试。参考:https://stackoverflow.com/questions/698
- 2021-12-14 10:01回答 1 已采纳 你这里提示错误是因为数组的长度为19429344 分割后的五维数组为(53018,1,17,25,25) 原始数组不能达到这个分割后的数组长度,所以不能分割.你需要检查x_1_25_final_arr
- 2020-01-15 14:28回答 2 已采纳 https://blog.csdn.net/zx520113/article/details/86228167
- 2021-05-07 16:02꧁ᝰ苏苏ᝰ꧂的博客 有了向量化,编写代码时无需使用显式循环。这些循环实际上不能省略,只不过是在内部实现,被代码中的其他结构代替。向量化的应用使得代码更简洁,可读性更强,也可以说使用了向量化方法的代码看上去更“Pythonic”。...
- 2022-02-27 17:28回答 2 已采纳 因为你没有准确的写什么时候退出循环,然后它就一直在那删,当列表里没有这个元素的时候你还去删,它就会报错
- 2022-12-25 17:07
 完美解决sklearn.exceptions.NotFittedError: This MinMaxScaler instance is not fitted yet. Call ‘fit‘ with克里斯的星星的博客 完美解决sklearn.exceptions.NotFittedError: This MinMaxScaler instance is not fitted yet. Call ‘fit‘ with
完美解决sklearn.exceptions.NotFittedError: This MinMaxScaler instance is not fitted yet. Call ‘fit‘ with克里斯的星星的博客 完美解决sklearn.exceptions.NotFittedError: This MinMaxScaler instance is not fitted yet. Call ‘fit‘ with - 2019-12-11 16:46senjie_wang的博客 关于Sklearn的归一化函数MinMaxScalar探讨引言正文实验一实验二实验二结论 引言 由于目前网上似乎没有博客详细介绍Sklearn的归一化函数MinMaxScalar到底是如何实现数据归一化的,而笔者也不确定生成的scalar的对象...
- 2020-11-21 11:08数据万花筒的博客 -------------------------- # ValueError Traceback (most recent call last) # in () # ----> 1 M + a # ValueError: operands could not be broadcast together with shapes (3,2) (3,) 这时候,你可能会像通过在...
- 2021-08-04 14:23あずにゃん的博客 人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新) import multiprocessing import numpy as np import tensorflow as tf from tensorflow.keras.preprocessing.image ...
- 2022-06-25 22:44Jenrey的博客 Python使用OpenCV进行计算机视觉处理,一文上手,直接毕业。自带停车场车位智能识别项目。由浅入深,无基础亦可学。
- 2024-02-24 02:05salvation~的博客 你将从可视化一个训练集的子集开始 In the cell below, the code randomly selects 64 rows from X, maps each row back to a 20 pixel by 20 pixel grayscale image and displays the images together. 下面的代码...
- 没有解决我的问题, 去提问
悬赏问题
- ¥15 怎么获取下面的: glove_word2id.json和 glove_numpy.npy 这两个文件
- ¥15 js调用html页面需要隐藏某个按钮
- ¥15 ads仿真结果在圆图上是怎么读数的
- ¥20 Cotex M3的调试和程序执行方式是什么样的?
- ¥20 java项目连接sqlserver时报ssl相关错误
- ¥15 一道python难题3
- ¥15 牛顿斯科特系数表表示
- ¥15 arduino 步进电机
- ¥20 程序进入HardFault_Handler
- ¥15 oracle集群安装出bug