
问题:在用xgboost做多分类学习时遇到了问题,参数均一样,训练集和验证集也是一样的,评估用的是自己写的评估函数ndcg算法,但是用xgb.train()和XGBClassifier().fit()后评估打分的差距相差太大,想问是predict的结果不一样嘛?为什么会有这种情况出现?
# 数据集整理均是一样的
X_train, X_test, y_train, y_test = train_test_split(xtrain_new,ytrain_new,test_size=0.2,random_state=RANDOM_STATE)
train_xgb = xgb.DMatrix(X_train, label= y_train)
test_xgb = xgb.DMatrix(X_test, label = y_test)
sklearn接口:_
# 用sklearn接口
xgb1 = XGBClassifier(max_depth=6,# 构建树的深度
learning_rate=0.1,# 如同学习率
n_estimators=100,#决策树数量
silent=False,
objective='multi:softprob',
booster='gbtree',
num_class=12,# 类别数
n_jobs=4,
gamma=0.2,
min_child_weight=1,
subsample=0.8,# 随机采样训练样本
colsample_bytree=0.7,# 生成树列采样
seed=RANDOM_STATE)# 随机种子
xgb_bst1 = xgb1.fit(X_train,y_train)
y_pred = xgb_bst1.predict(X_test)
test_ndcg_score = ndcg_score(y_test, y_pred, k=k_ndcg)
print(test_ndcg_score) #评估打分
结果: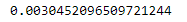
下面是原生接口:
# 下面是原生接口,参数也是一样
params={
'max_depth':6,# 构建树的深度,越大越容易过拟合
'eta':0.1,# 如同学习率
'num_round':100,#决策树数量
'objective':'multi:softprob',# 多分类的问题
'booster':'gbtree',
'num_class':12,# 类别数,与 multisoftmax 并用
'n_jobs':4,
'gamma':0.2,# 用于控制是否后剪枝的参数,越大越保守
'min_child_weight':1,
'subsample':0.8,# 随机采样训练样本
'colsample_bytree':0.7,
'seed':RANDOM_STATE# 随机种子
}
watchlist = [ (train_xgb,'train'), (test_xgb, 'test') ]
# 训练模型
xgb2 = xgb.train(params,
train_xgb,
params['num_round'],
watchlist,
feval = customized_eval,
verbose_eval = 3,
early_stopping_rounds = 5)
# 预测模型评估
y_pred = np.array(xgb2.predict(test_xgb))
test_ndcg_score = ndcg_score(y_test, y_pred, k=k_ndcg)
print(test_ndcg_score)# 评估打分
结果: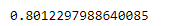
ndcg_score函数是自己写的,multi:softprob的输出应该是一个概率矩阵,不明白为什么评估差距很大,希望有人能解答!!谢谢!!






