
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.layout import LAParams, LTTextBox, LTImage, LTFigure
from pdfminer.converter import PDFPageAggregator
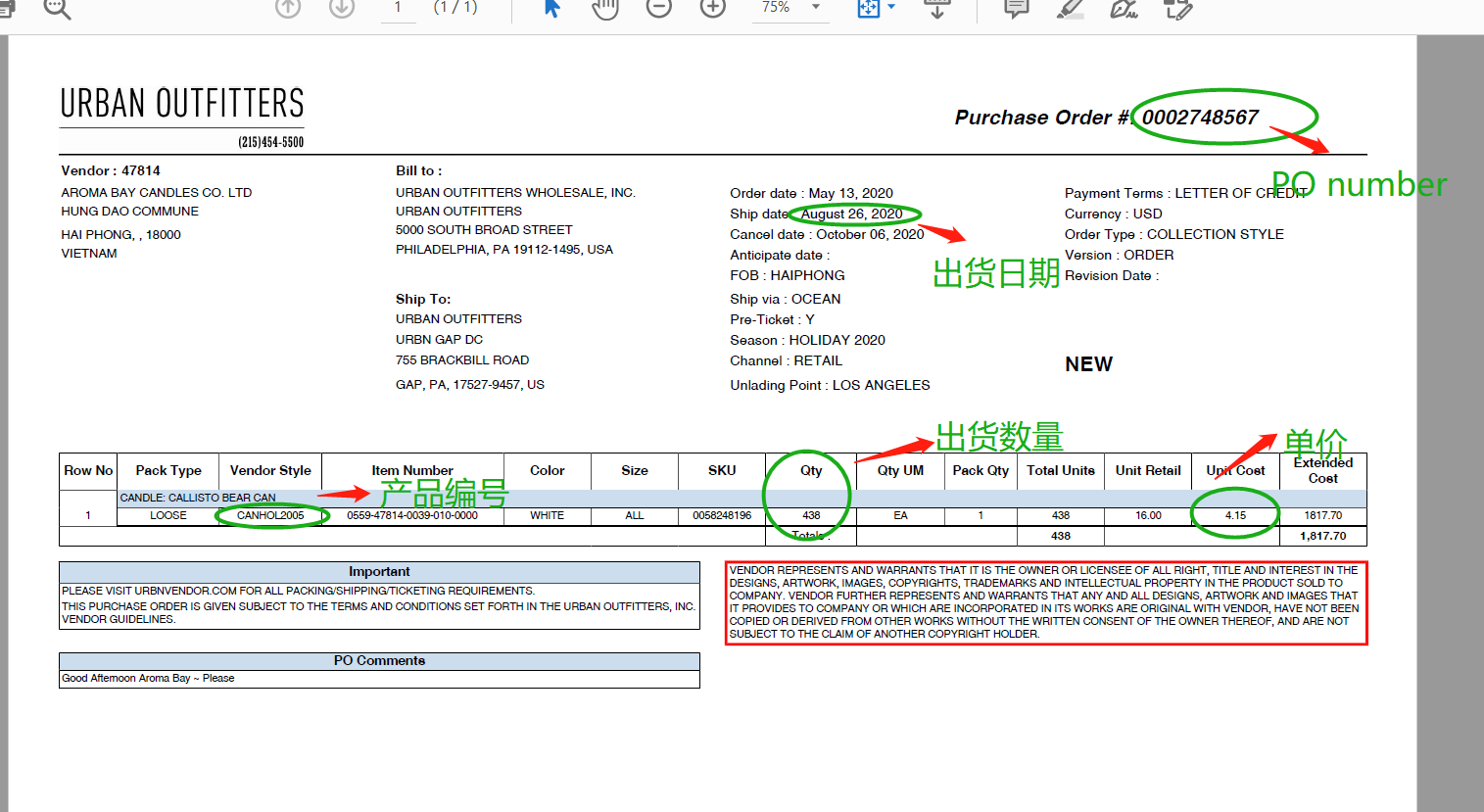
#打开pdf文件
fp = open('E:\py_pdf\PurchaseOrder#0002748567(0514).pdf','rb')
#从文件句柄创建一个pdf解析对象
parser = PDFParser(fp)
#创建pdf文档对象,存储文档结构
document = PDFDocument(parser)
#创建一个pdf资源管理对象,存储共享资源
rsrcmgr = PDFResourceManager()
laparams = LAParams()
#创建一个device对象
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
#创建一个解释对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
#处理包含在文档中的每一页
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
layout = device.get_result()
for x in layout:
# 获取文本对象
if isinstance(x, LTTextBox):
print(x.get_text().strip())
因为刚接触接下来抽取指定字段有点不会,希望大神讲解






