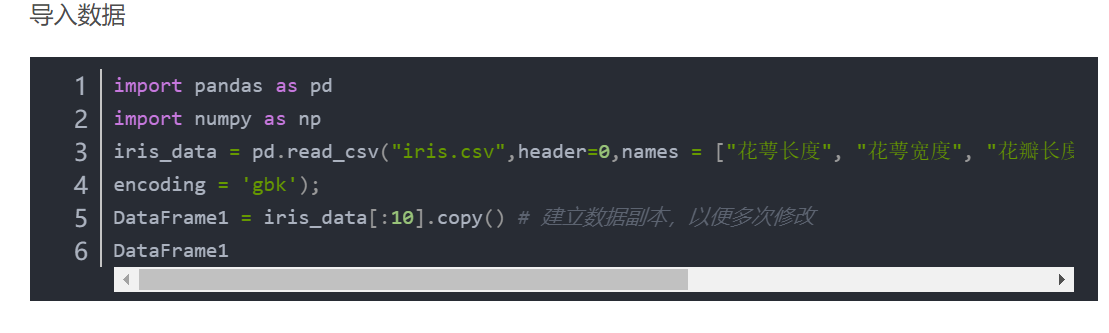
指定系统解码列名为中文;由于系统默认utf-8所以一般不需指定 。
我在pycharm中测试
当你发现有乱码才考虑用encode
以下是测试程序:
import pandas as pd,numpy as np
iris_data=pd.read_csv(r"C:\Users\Administrator\Desktop\iris.csv")
df=iris_data[:10].copy()
print(df.head(3))
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
iris_data=pd.read_csv(r"C:\Users\Administrator\Desktop\iris.csv",header=0,names=['长度1','宽度1','长度2','宽度2','物种'])
df=iris_data[:10].copy()
print(df.head(3))
iris_data=pd.read_csv(r"C:\Users\Administrator\Desktop\iris.csv",header=0,names=['长度1','宽度1','长度2','宽度2','物种'],encoding='gbk')
df=iris_data[:10].copy()
print(df.head(3))
iris_data=pd.read_csv(r"C:\Users\Administrator\Desktop\iris.csv",header=0,names=['长度1','宽度1','长度2','宽度2','物种'],encoding='utf-8')
df=iris_data[:10].copy()
print(df.head(3))
iris_data=pd.read_csv(r"C:\Users\Administrator\Desktop\iris.csv",header=0,names=['长度1','宽度1','长度2','宽度2','物种'],encoding='ascii')
df=iris_data[:10].copy()
print(df.head(3))
C:\ProgramData\Anaconda3\python.exe C:/Users/Administrator/Desktop/Fastener/Dlg/临时.py
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
长度1 宽度1 长度2 宽度2 物种
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
长度1 宽度1 长度2 宽度2 物种
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
长度1 宽度1 长度2 宽度2 物种
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
长度1 宽度1 长度2 宽度2 物种
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
Process finished with exit code 0