
问题描述:
在平台的Kafka集群环境(kafka01,kafka02,kafka03)中 ,出现了kafka01 CPU负载高,另外两台节点Kafka02, Kafka03 CPU负荷低的问题:
Grafana监控如下
CPU:kafka01明显高很多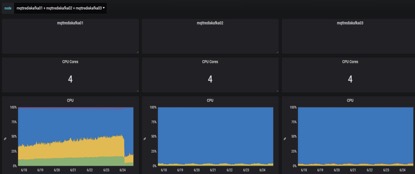
流量:kafka01明显高很多,in/out大概是kafka02,kafka03的5倍
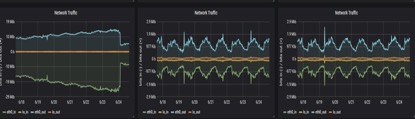
问题定位:
1.查询topic:我们的topic都是三分区,三副本的。
2.查询topic分区:可以看到这个3分区,3副本的分区,leader的分配是不均衡的。有两个分区的leader都是1。
3.查询topic消费:可以看到topic的分区数据量都是差不多的。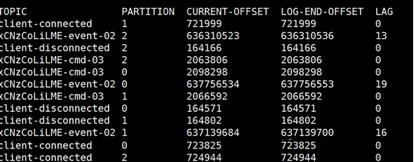
请教大神:问题出在哪里,该怎么解决,谢谢!



