我在用xpath helper插件都可以检索到:
但是运行时的显示值是None或者[]。
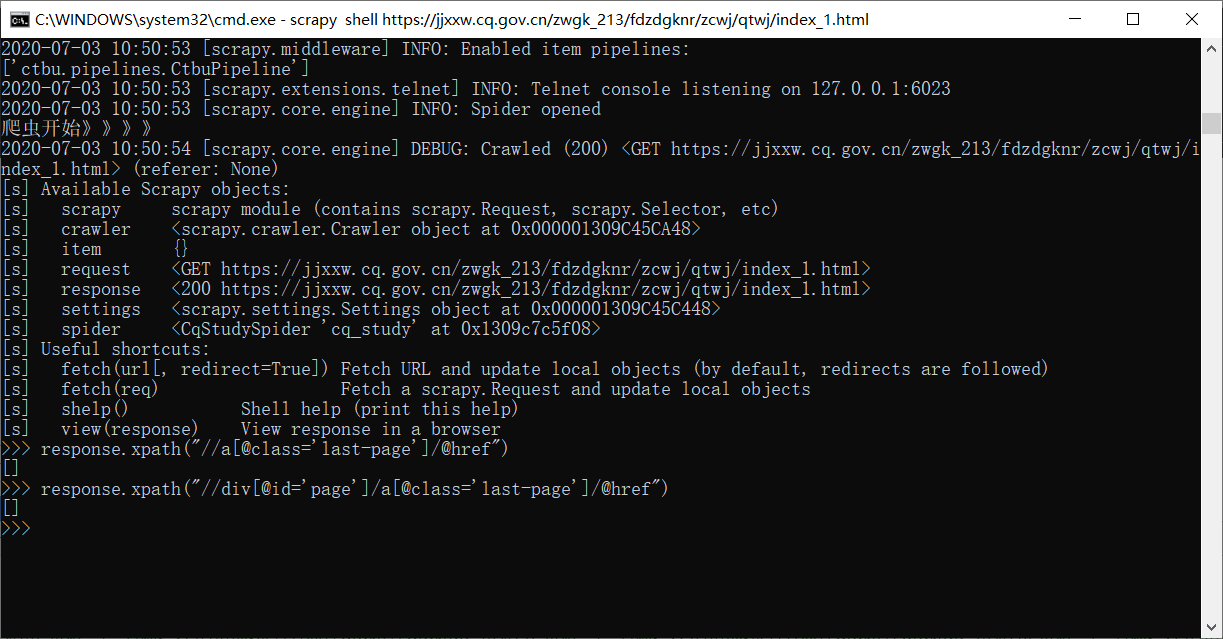
这是scrapy shell的解析:
收起
考虑网页的内容使用了ajax,使用右键-》查看网页源代码,看是否仍然能获得指定的内容
报告相同问题?


 分享
分享 分享
分享

