

求助:Python爬虫学术网址时,更换网址后,显示list index out of range,问题出在哪?应如何解决?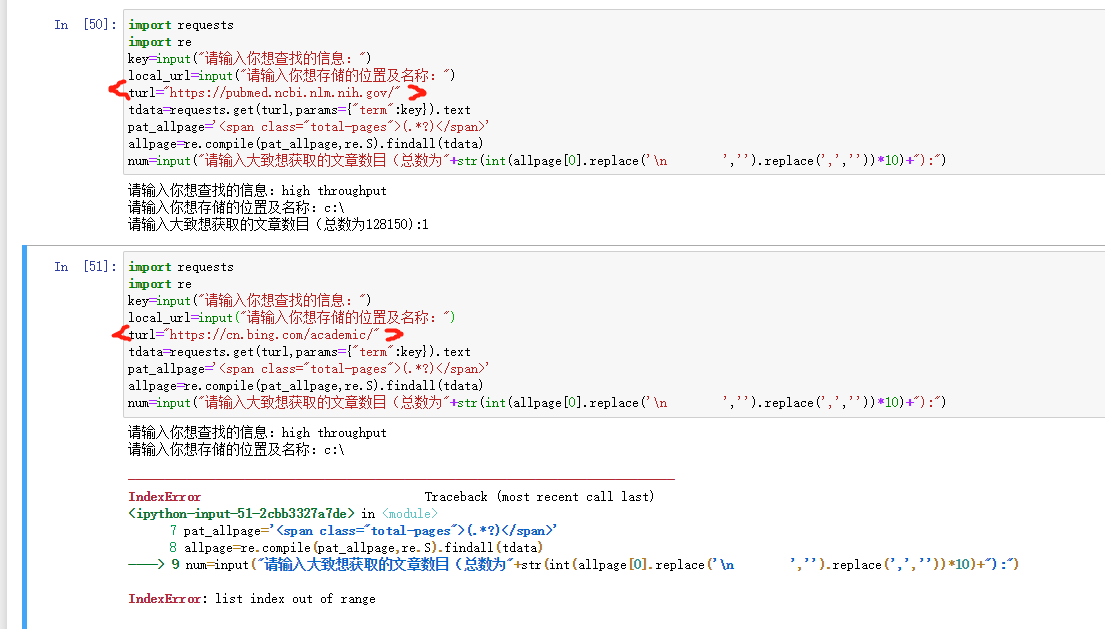
import requests
import re
key=input("请输入你想查找的信息:")
local_url=input("请输入你想存储的位置及名称:")
turl="https://cn.bing.com/academic/"
tdata=requests.get(turl,params={"term":key}).text
pat_allpage='(.*?)'
allpage=re.compile(pat_allpage,re.S).findall(tdata)
num=input("请输入大致想获取的文章数目(总数为"+str(int(allpage[0].replace('\n ','').replace(',',''))*10)+"):")




