最近在看索引优化相关的内容,有个知识点让我很疑惑。
举个例子:
create index index_c1c2c3 on table1(c1,c2,c3)
在表table1的c1,c2,c3三个字段创建复合索引,这个时候执行两条sql语句
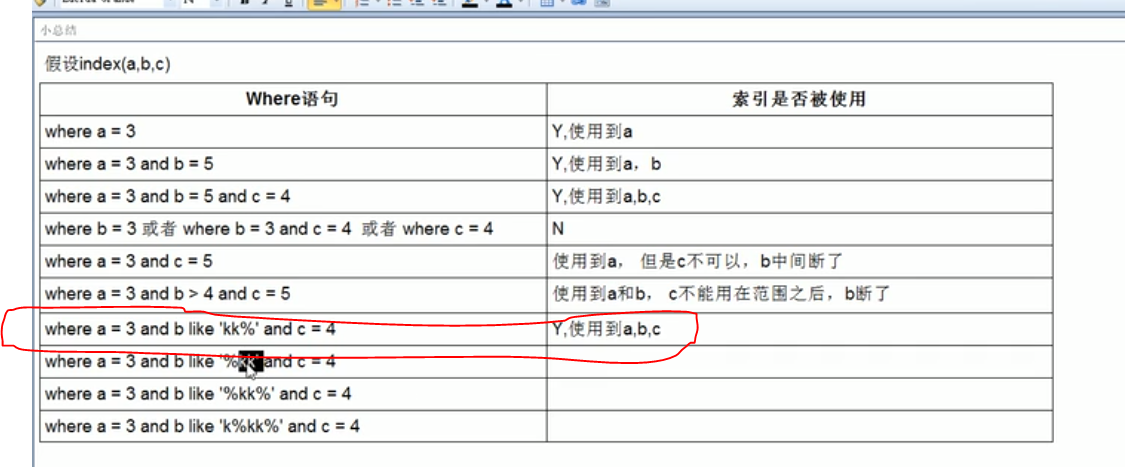
1、select * from table1 where c1=a and c2>b and c3=c;
对该语句来说,因为c2列用了范围查询,导致复合索引只用了c1、c2两个字段,c3没用到。基于B+树的数据结构的话我觉得是没有问题。
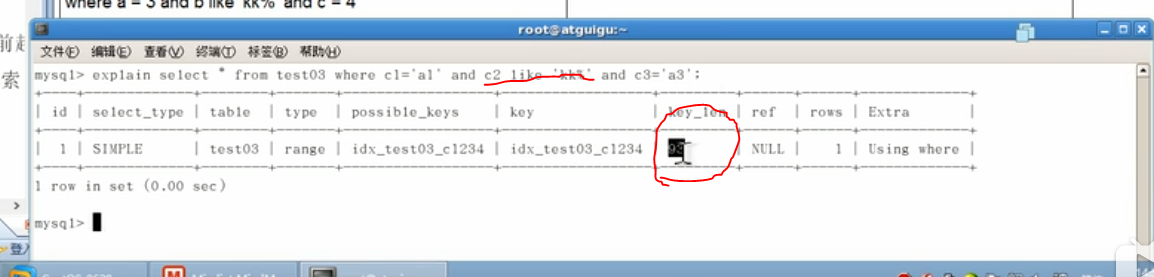
2、select * from table1 where c1=a and c2 like 'c%' and c3=c;
对该语句来说,反而是三个索引都用到了,但是like的效果不是和范围查询一样吗?反正反B+树的数据结构来思考我是理解不了。各位大佬能帮忙解释一下吗?还是优化器在其中起作用了?
具体的实例如下,按B+树的结构来说,使用c2使用like后因为是范围查询,c3应该是无序的,怎么用索引呢?
图片