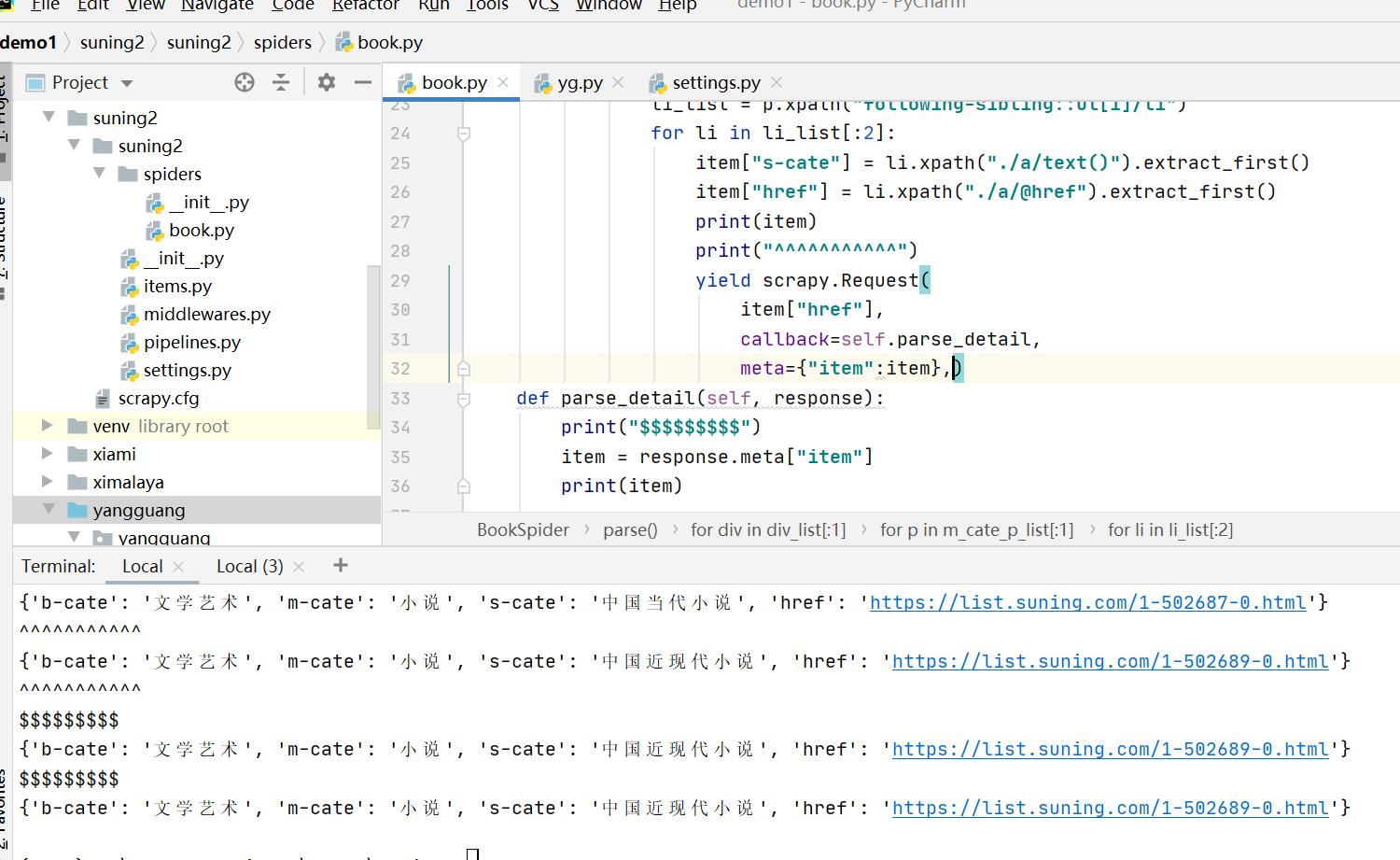
我本身以为第三个输出应该是中国当代小说,可是却不是,为什么第一次爬取时32行meta传过去的item和第二次的相同,是yield的问题吗

scrapy爬虫时的yield问题

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新

- 2024-07-06 23:16WishYouAFortune的博客 Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。...Scratch,是抓取的意思,这个Python的爬虫框架叫Scrapy,大概也是这个意思吧,就叫它:小抓抓吧。
- 2024-02-04 08:49### Python爬虫Scrapy实例详解 ...通过以上步骤,你已经成功创建了一个基本的Scrapy爬虫项目,并了解了各个文件的作用及其配置方法。接下来,你可以根据实际需求进一步定制爬虫逻辑,实现更复杂的爬虫功能。
- 2024-03-26 13:44言程序plus的博客 Scrapy 是用 Python 实现的一个为了采集网站数据、提取结构性数据而编写的应用框架。常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定...
- 2021-05-07 11:56麦芽糖0219的博客 scrapy的工作流程 scrapy的入门使用 scrapy数据建模与请求 scrapy模拟登陆 scrapy管道的使用 scrapy中间件的使用 scrapy_redis...scrapy的日志信息与配置 scrapyd部署scrapy项目 Gerapy爬虫管理 crawlspider类的使用
- 2024-04-20 14:43### Python爬虫Scrapy培训源码解析 #### 一、Python爬虫简介 在当今互联网时代,数据成为了宝贵的资源之一。而爬虫技术作为一种高效的数据抓取手段,在数据收集方面发挥着不可替代的作用。Python语言因其简洁易读...
- 2025-04-08 22:21木觞清的博客 它提供了完整的爬虫开发工具,包括请求管理、数据解析、存储和异常处理等功能,适用于数据挖掘、监测和自动化测试等场景。通过灵活的中间件和管道机制,Scrapy 可以轻松扩展功能(如代理池、分布式爬取)。如果你...
- 2023-01-09 18:20Shinersmile的博客 在scrapy中,会专门定义一个用于记录数据的类,实例化一个对象,利用这个对象来记录数据。每一次,当数据完成记录,它会离开spiders,来到Scrapy Engine(引擎),引擎将它送入Item Pipeline(数据管道)处理。定义...
- 2024-11-21 21:53易辰君的博客 而 Scrapy 作为一个功能强大且高效的 Python 爬虫框架,以其模块化、异步处理和高度可扩展性,广泛应用于数据挖掘、监控和分析等领域。本指南将从 Scrapy 的基础概念到项目实践,带你全面了解如何搭建和优化一个 ...
- 2020-09-18 20:37在实际使用Scrapy爬虫时,你可能会遇到各种问题,例如反爬机制、动态加载内容、编码问题等。这些问题需要通过技术手段如设置User-Agent、使用中间件处理JavaScript、处理编码转换等来解决。同时,了解HTTP协议和网页...
- 2024-12-12 14:03计算机软件程序设计的博客 在Scrapy中,Item是被用来保存抓取到的数据的容器。你可以定义自己的Item类,类似于Python字典,但是提供了额外保护机制和便利方法。Item通常定义在items.py文件中。
- 2023-07-10 02:24ζ小菜鸡的博客 大家好我是小菜鸡,让我们一起学习Python的网络爬虫框架-Scrapy爬虫框架的使用(一起努力,咱们顶峰相见!!!)
- 2023-03-03 08:52q56731523的博客 前几天我有用过Scrapy架构编写了一篇爬虫的代码案例深受各位朋友们喜欢,今天趁着热乎在上一篇有关Scrapy制作的爬虫代码,相信有些基础的程序员应该能看的懂,很简单,废话不多说一起来看看。
- 2020-12-08 10:18weixin_39600331的博客 本文主要通过实例介绍了scrapy框架的使用,分享了两个例子,爬豆瓣文本例程 douban 和图片例程 douban_imgs ,具体如下。例程1: douban目录树douban--douban--spiders--__init__.py--bookspider.py--douban_comment...
- 2023-11-20 11:25向之 所欣的博客 网页的域名 (3)爬虫文件的基本组成: 继承scrapy.Spider类 name = ‘baidu’ --> 运行爬虫文件时使用的名字 allowed_domains --> 爬虫允许的域名,在爬取的时候,如果不是此域名之下的url 会被过滤掉...
- 2020-03-21 15:44JJH的创世纪的博客 Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试. 其最初是为了页面抓取 (更确切来说, 网络抓取 ...
- 2024-07-17 17:18Python_trys的博客 Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。光学理论是没用的,要学会跟着一起敲,要动手...
- 2024-02-02 20:51蜀道之南718的博客 Scrapy shell是Scrapy框架提供的一个交互式shell工具,用于快速开发和调试爬虫。它允许用户在不启动完整爬虫程序的情况下,以交互的方式加载和请求网页,并使用选择器和Scrapy的API来提取和处理数据。
- 2021-07-13 19:23GitLqr的博客 Scrapy 是一个 python 编写的,被设计用于爬取网络数据、提取结构性数据的开源网络爬虫框架。 作用:少量的代码,就能够快速的抓取 官方文档:https://scrapy-chs.readthedocs.io/zh_CN/0.24/ 补充:Scrapy 使用...
- 2020-09-21 00:51### Python中Scrapy爬虫图片处理详解 #### 一、Scrapy爬虫简介及应用场景 Scrapy是一款用于Python的快速高级网页爬取框架,适用于多种数据提取需求,包括但不限于新闻站点、产品信息、用户评论等。它具备强大的...
- 2024-07-21 14:00月流霜的博客 当你写了很多个爬虫程序之后,你会发现每次写爬虫程序时,都需要将页面获取、页面解析、爬虫调度、异常处理...Scrapy 是基于 Python 的一个非常流行的网络爬虫框架,可以用来抓取 Web 站点并从页面中提取结构化的数据。
- 没有解决我的问题, 去提问

