
技术框架:selenium + browsermob-proxy
selenium 获取页面元素
browsermob-proxy 获取请求信息
场景1:打开Chrome,输入localhost:8082,在NetWork中可以看到有23个请求,并且其中有我要的业务请求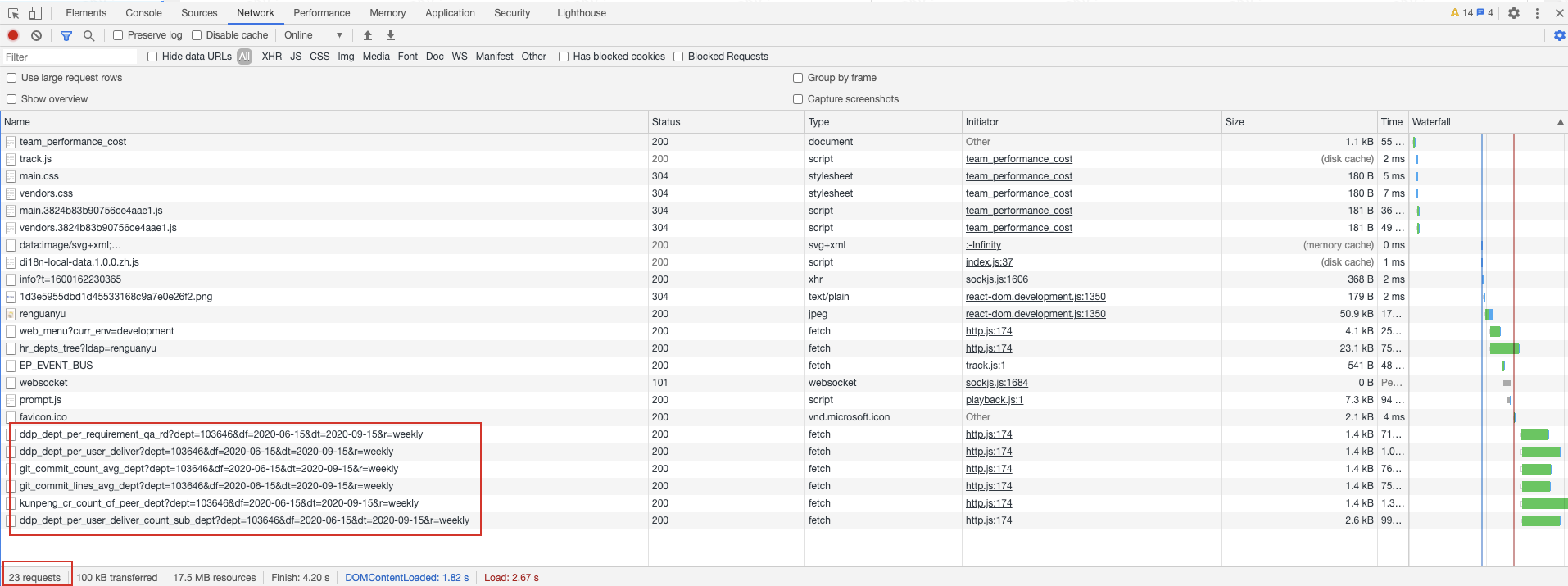
场景2:通过selenium + browsermob-proxy程序,打开localhost:8082,只能获取到6个请求,其他请求丢失了,这是为什么呢?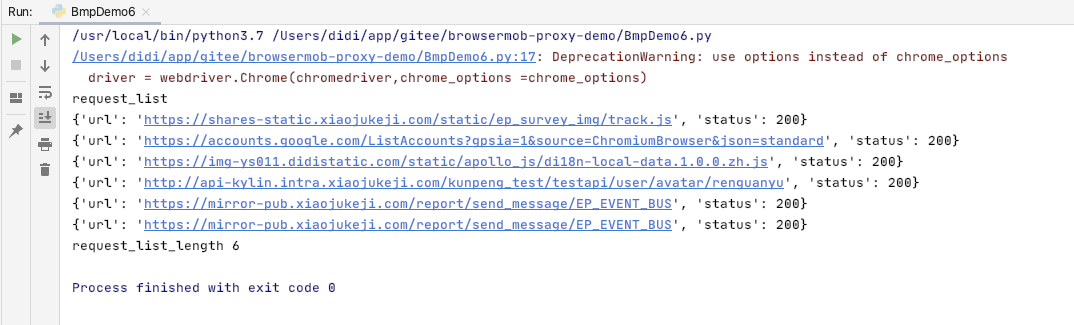
我的代码
from browsermobproxy import Server
from selenium import webdriver
import os
from urllib import parse
from time import sleep
server = Server(r'/Users/renguanyu/app/browsermob-proxy/2.1.4/bin/browsermob-proxy')
server.start()
proxy = server.create_proxy()
chromedriver = "/usr/local/bin/chromedriver"
os.environ["webdriver.chrome.driver"] = chromedriver
url = parse.urlparse (proxy.proxy).path
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--ignore-certificate-errors')
chrome_options.add_argument("--proxy-server={0}".format(url))
driver = webdriver.Chrome(chromedriver,chrome_options =chrome_options)
driver.implicitly_wait(60)
proxy.new_har("http://localhost:8082/", options={'captureHeaders': True,'captureContent': True})
driver.get("http://localhost:8082/")
sleep(3)
# 打印network
result = proxy.har
log = result["log"]
entries = log["entries"]
list = []
for entrie in entries:
request = entrie["request"]
request_url = request["url"]
response = entrie["response"]
status = response["status"]
dict = {
"url": request_url,
"status": status
}
list.append(dict)
# sleep(30)
print("request_list")
for item in list:
print(item)
print("request_list_length", len(list))
proxy.close()
driver.quit()




