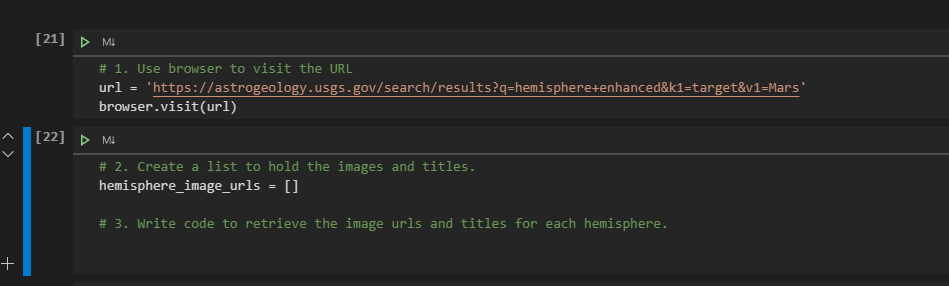
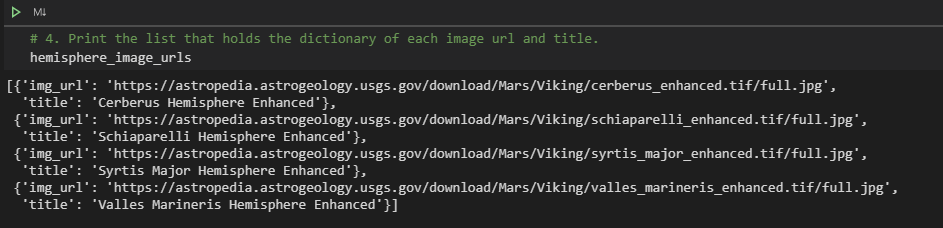
我有一个作业,然后其中有一题是让我去nasa的一个网站上去scrape火星的照片,然后获取图片的url和title, 这道题里面的建议就是用for loop去获得所有的照片的url和title. 但是我不太清楚怎么做?
我会附几张照片然后有没有大神能帮我看看怎么弄?
我这个code算是对的嘛?
images = soup.find_all("img", class_='thumb').get("src", "alt")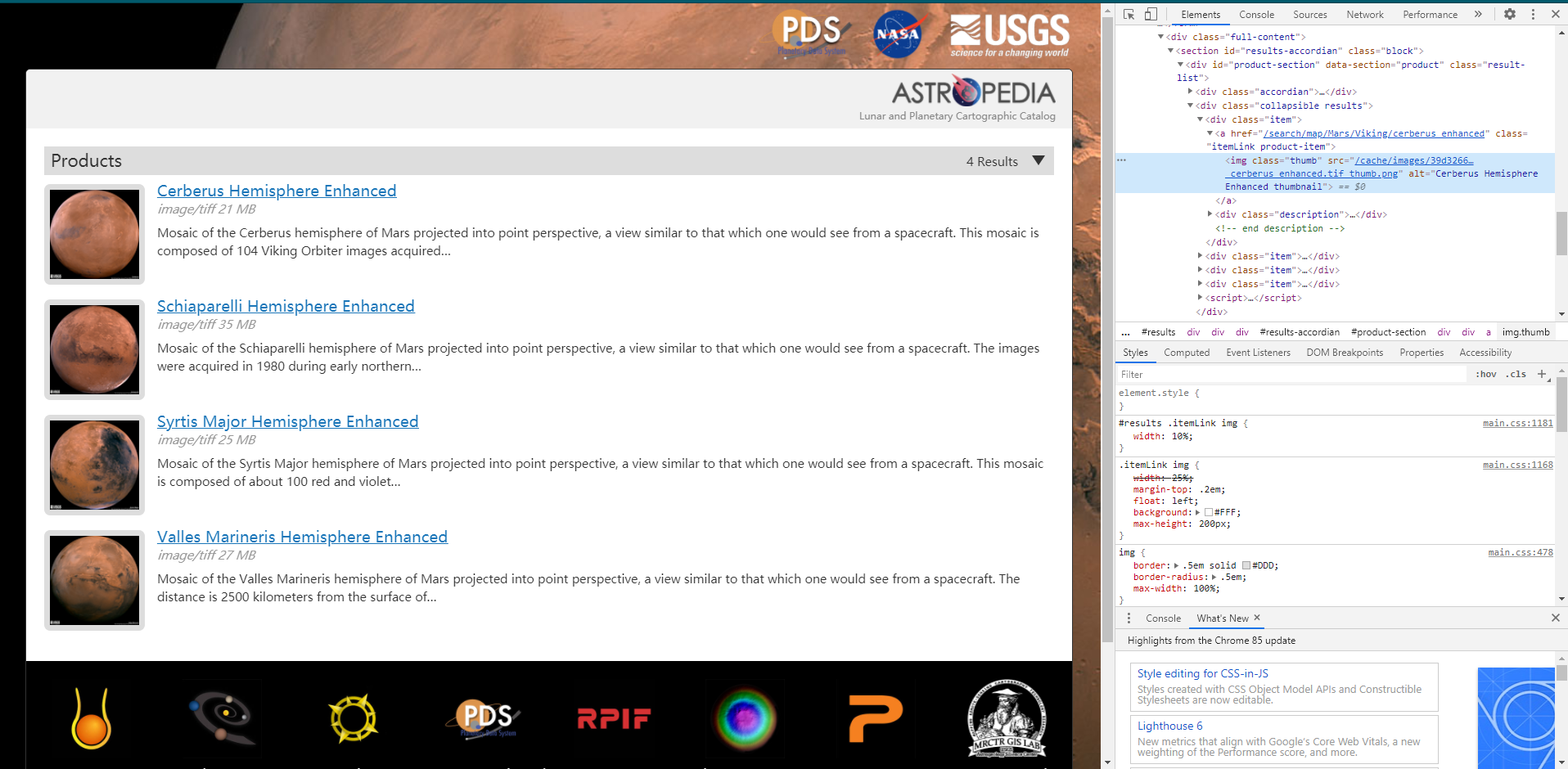

我有一个作业,然后其中有一题是让我去nasa的一个网站上去scrape火星的照片,然后获取图片的url和title, 这道题里面的建议就是用for loop去获得所有的照片的url和title. 但是我不太清楚怎么做?
我会附几张照片然后有没有大神能帮我看看怎么弄?
我这个code算是对的嘛?
images = soup.find_all("img", class_='thumb').get("src", "alt")
 分享
分享




