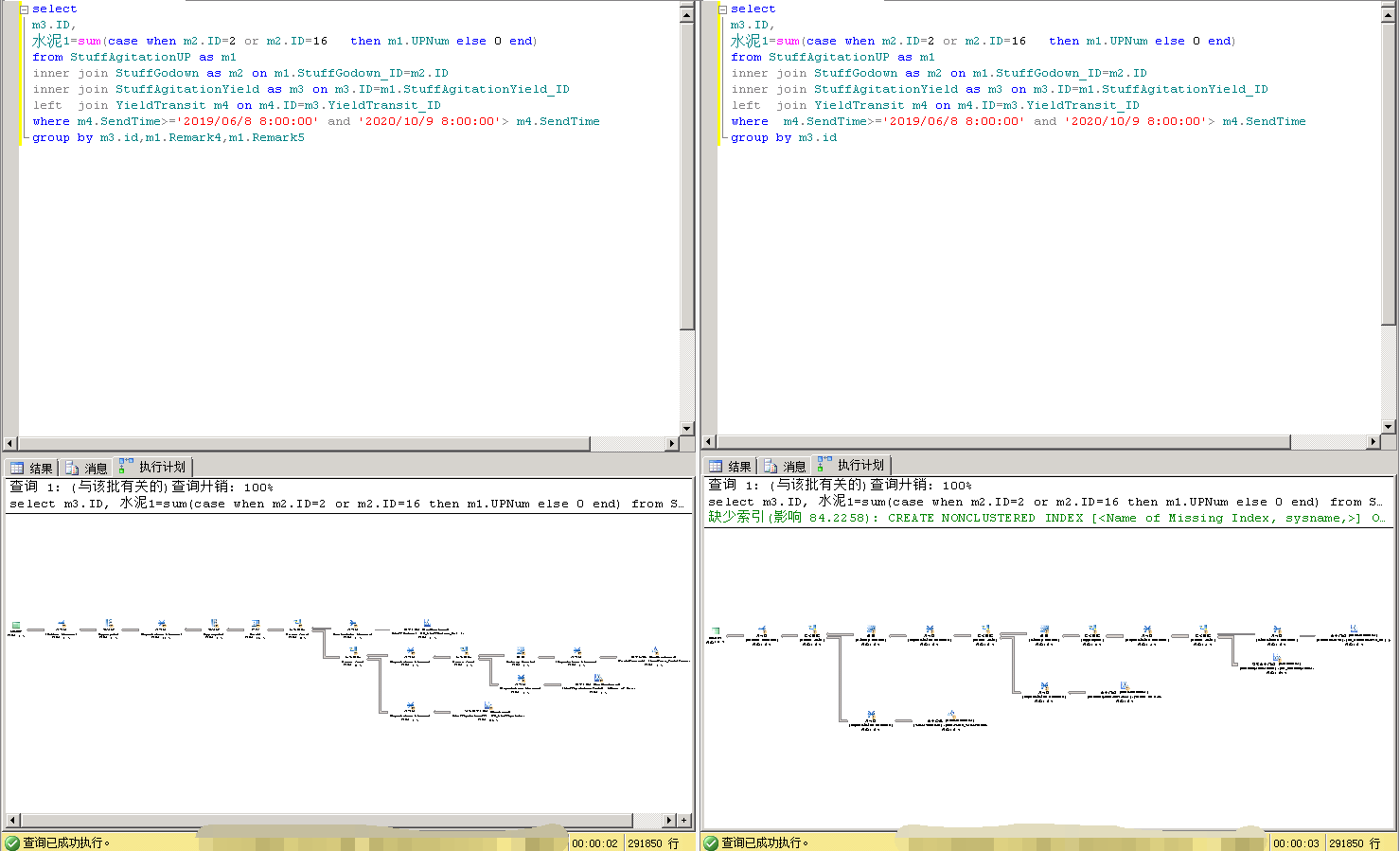
可以看到两边的实际执行计划有差异,但两边所用索引是一致的,我能理解实际执行计划有差异必然带来查询耗时的差异。我奇怪的是左边group by 字段要别右边更多,但耗时却更少。
这是为什么?
我的认知中,分组字段越多,所用耗时应该越长才对,怎么会有做更多的事情反而耗时更少呢?
或者说我的认知没有问题,只是sql server给出的执行计划本身有问题?那么我应该怎么做才能让它正常呢?因为所用的索引都是一致的,强制指定索引影响查询计划应该是没有意义的,还有别的办法吗?

可以看到两边的实际执行计划有差异,但两边所用索引是一致的,我能理解实际执行计划有差异必然带来查询耗时的差异。我奇怪的是左边group by 字段要别右边更多,但耗时却更少。
这是为什么?
我的认知中,分组字段越多,所用耗时应该越长才对,怎么会有做更多的事情反而耗时更少呢?
或者说我的认知没有问题,只是sql server给出的执行计划本身有问题?那么我应该怎么做才能让它正常呢?因为所用的索引都是一致的,强制指定索引影响查询计划应该是没有意义的,还有别的办法吗?
 分享
分享
应该是m1.Remark和m2.REmark都有索引,分组不用回表了,id会扫描所有数据,可以用explain看一下
分享

