想要做一个自动爬取公司内网word的一个工具,但是在爬取日期的时候,发现爬出来的源码缺失了很多信息,跟F12看到的不一样。
尝试用了xpath和正则表达式解析,解析出来的全是空列表。
搜了很多,基本都说是异步加载的问题。
但查Network里看到的是第一条出来的,Doc里的内容。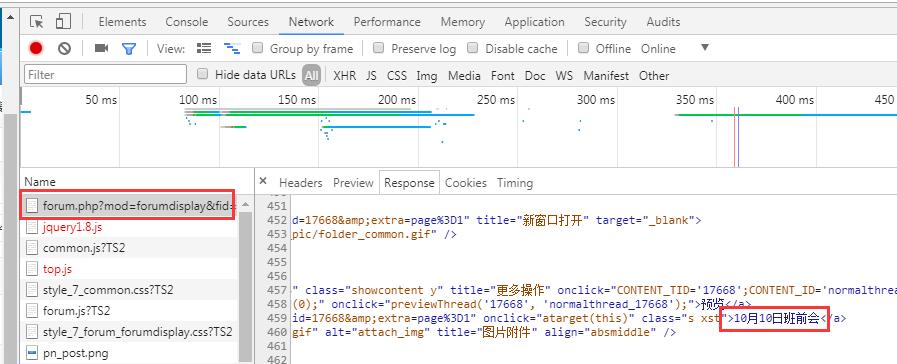
所以应该不是异步加载的关系。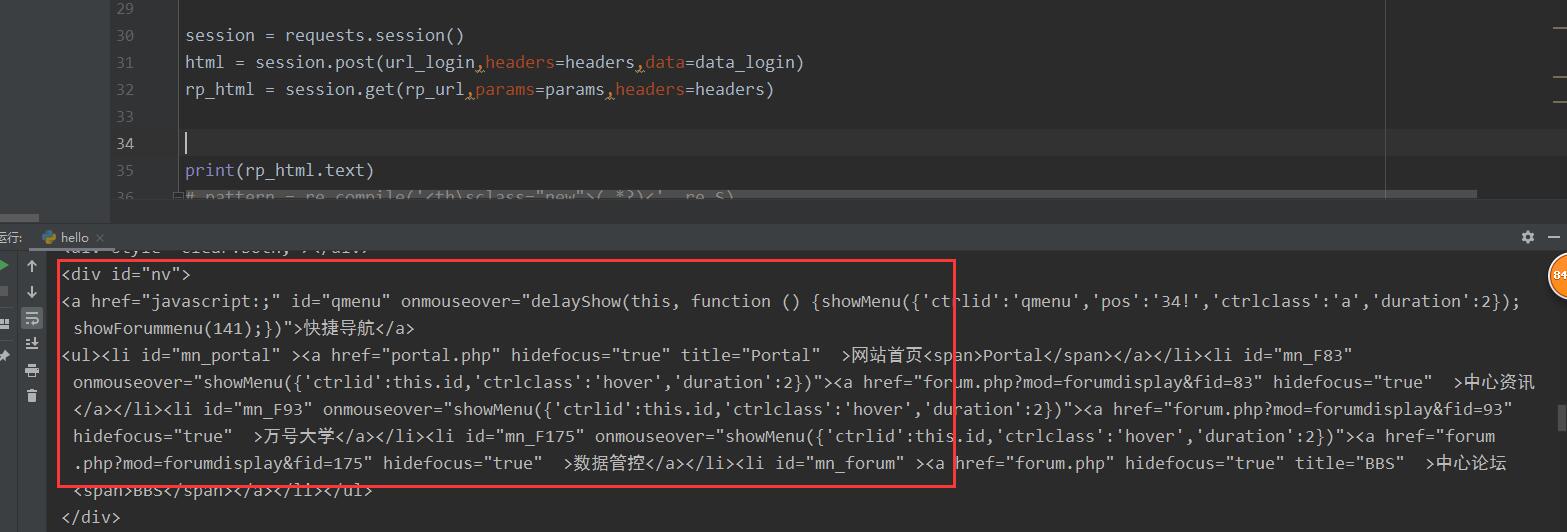
这是爬出来的源码,里面只有一些标题,并不包含实际内容
——————————
卡着好几天了,实在没辙了,哪位大佬有啥办法没。

想要做一个自动爬取公司内网word的一个工具,但是在爬取日期的时候,发现爬出来的源码缺失了很多信息,跟F12看到的不一样。
尝试用了xpath和正则表达式解析,解析出来的全是空列表。
搜了很多,基本都说是异步加载的问题。
但查Network里看到的是第一条出来的,Doc里的内容。
所以应该不是异步加载的关系。
这是爬出来的源码,里面只有一些标题,并不包含实际内容
——————————
卡着好几天了,实在没辙了,哪位大佬有啥办法没。
 分享
分享 把浏览器 源码,跟爬取的源码 全部贴出来
分享


