查找了相关资料,目前python中对pdf表格的抽取主要采用的是pdfplumber、camelot、tabula等,但都是针对完整且相对规范的表格。但对形如下图所示的表格的数据提取,出现了文本表格混排,跨页面表格的衔接等问题,请求大佬指点!
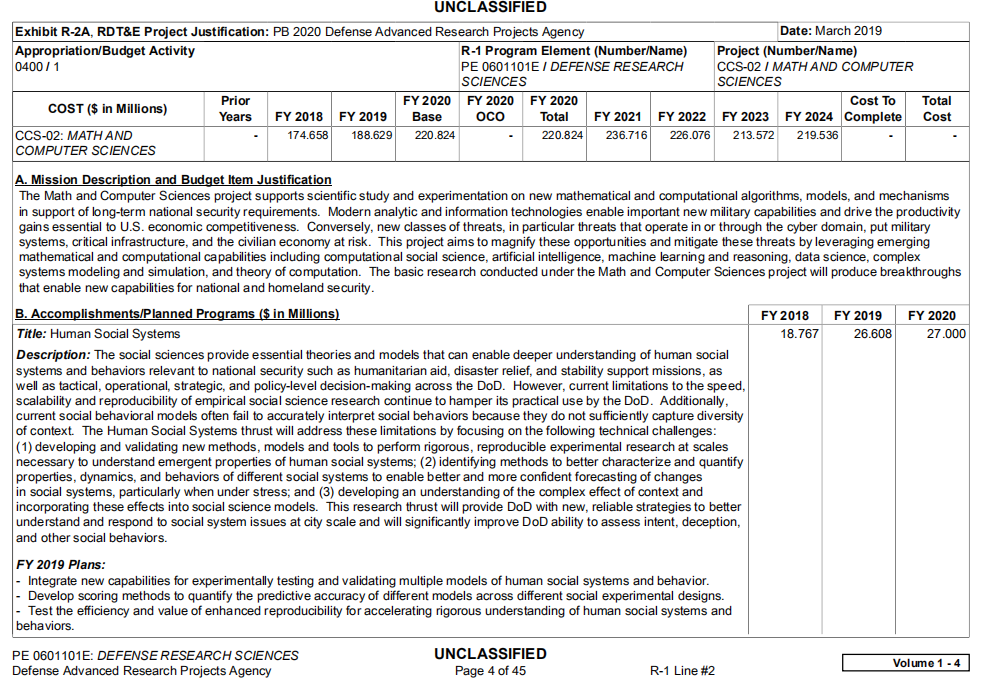
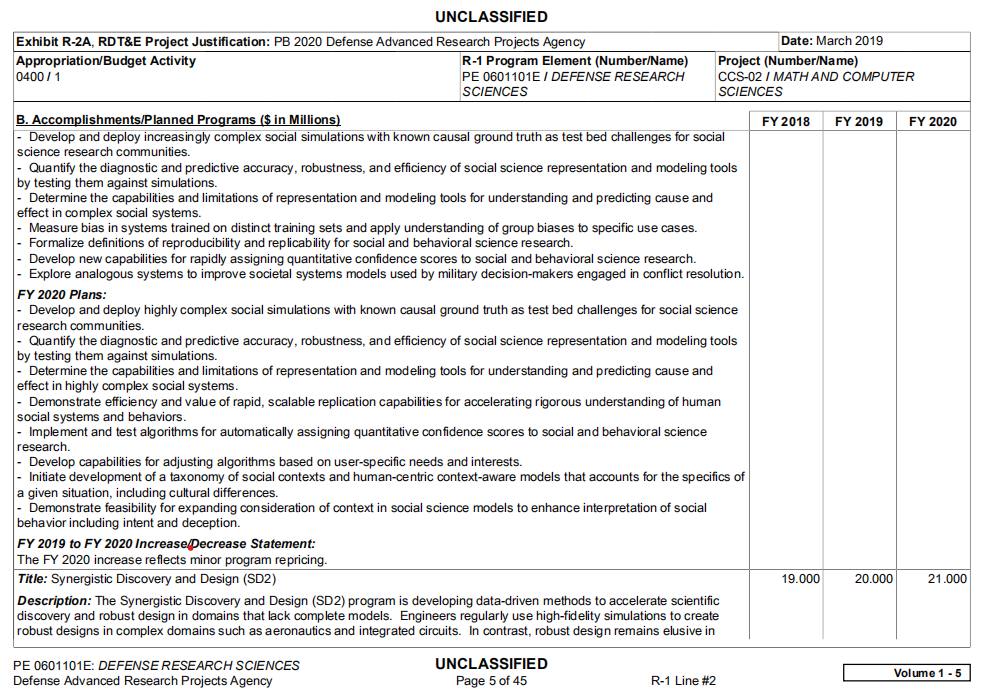

查找了相关资料,目前python中对pdf表格的抽取主要采用的是pdfplumber、camelot、tabula等,但都是针对完整且相对规范的表格。但对形如下图所示的表格的数据提取,出现了文本表格混排,跨页面表格的衔接等问题,请求大佬指点!
 分享
分享
同问,还有那种表格分别只在页面一边的情况(页面排版是左右两边分开分布),这种有时候读文本内容都困难。。。
分享


