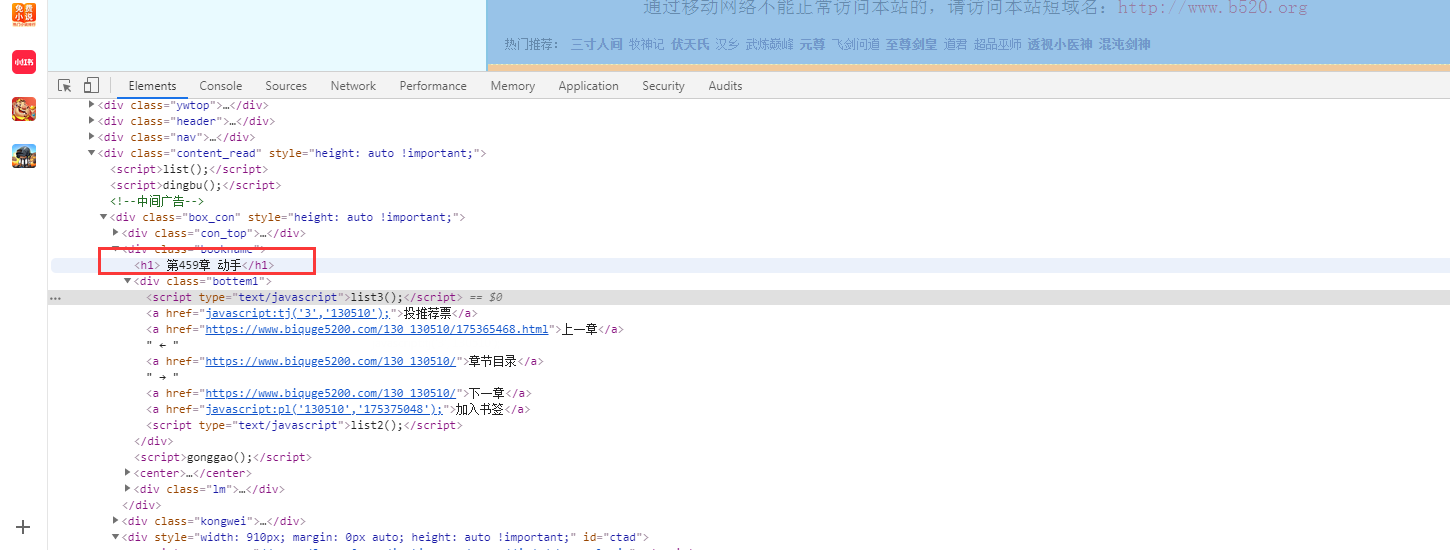
爬取网页文件时,我想只选出目录中的内容,用什么方法好进行判断!
也就是说怎么找到网页代码中一级代码下边的第一级的内容,不继续往下延伸。

爬取网页内容时只筛选一级内容下的首行内容,不做往下延伸

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答 默认 最新

悬赏问题
- ¥15 python中合并修改日期相同的CSV文件并按照修改日期的名字命名文件
- ¥15 有赏,i卡绘世画不出
- ¥15 如何用stata画出文献中常见的安慰剂检验图
- ¥15 c语言链表结构体数据插入
- ¥40 使用MATLAB解答线性代数问题
- ¥15 COCOS的问题COCOS的问题
- ¥15 FPGA-SRIO初始化失败
- ¥15 MapReduce实现倒排索引失败
- ¥15 ZABBIX6.0L连接数据库报错,如何解决?(操作系统-centos)
- ¥15 找一位技术过硬的游戏pj程序员