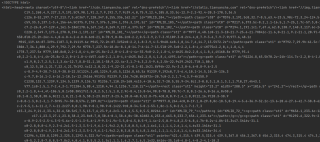
之前在调试的时候改了一个配置文件,编码为ASCII改成了utf-8.但是忘记了配置文件的名称。好像是(clines.py)!代码如下。。
def main():
baseurl = 'https://www.tianyancha.com/search?key={}&base=hun'
r = getdata(baseurl)
print(r)
# 获取href数据
def getdata(baseurl):
datalist = []
for url in (baseurl.format(parse.quote(i)) for i in list_cp()[0]):
print(url)
html = ask_url(url)
soup = BeautifulSoup(html, "html.parser")
print(soup)
def ask_url(url):
head = {"user-agent": " Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome"
"/""81.0.4044.138 Safari/537.36"}
req = urllib.request.Request(url, headers=head)
html = ""
response = urllib.request.urlopen(req)
html = response.read()
return html
# 公司列表
def list_cp():
tb = []
with open("名单.csv", "r", encoding="utf-8") as file:
cp = file.readlines()
for i in range(0, len(cp)):
cp[i] = cp[i].rstrip('n')
tb.append(cp)
# print(cp)
return tb
if __name__ == "__main__":
main()
print("OK")
下面是soup打印出来的页面,完全是乱的。。