


2条回答 默认 最新

 关注
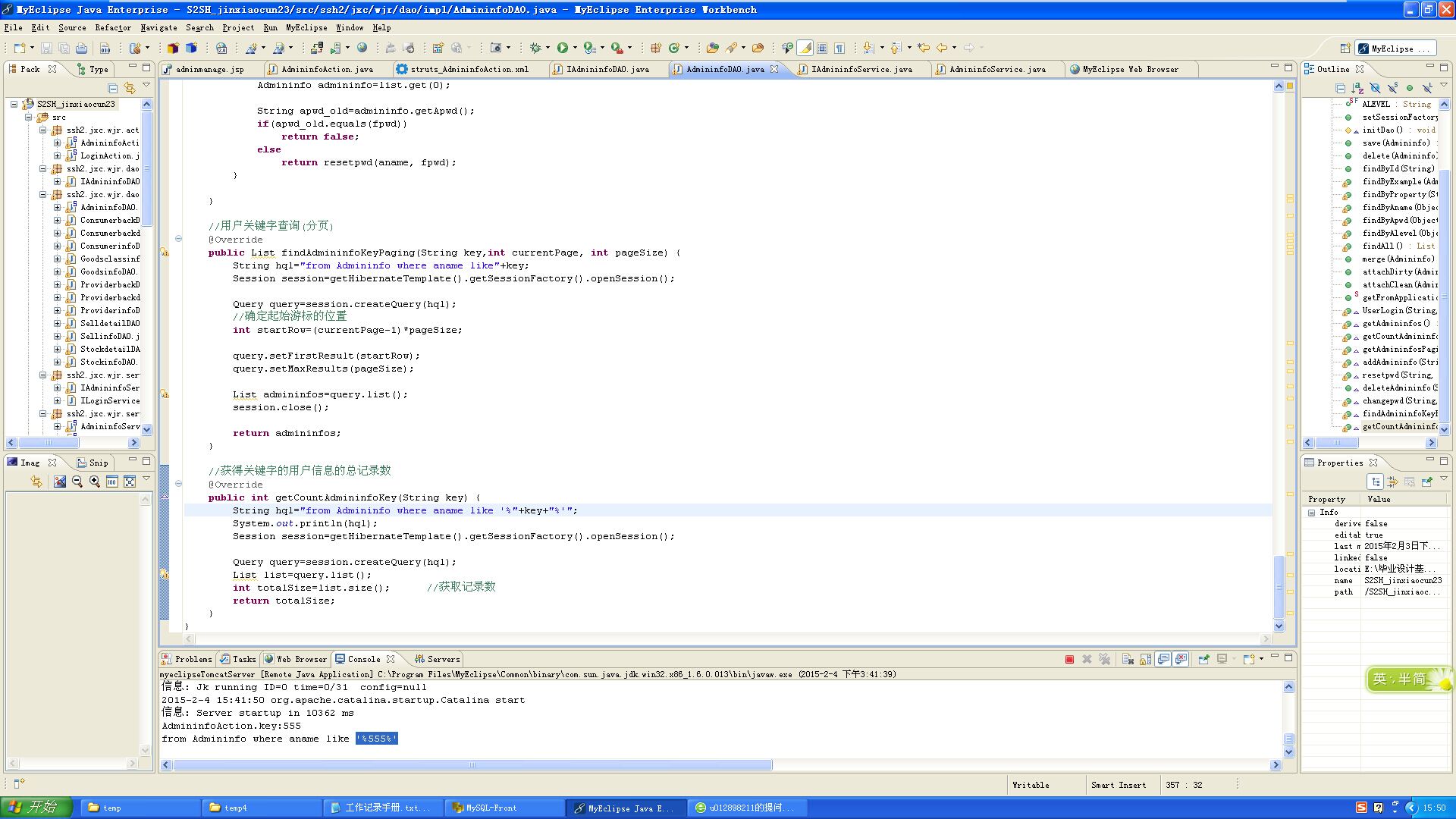
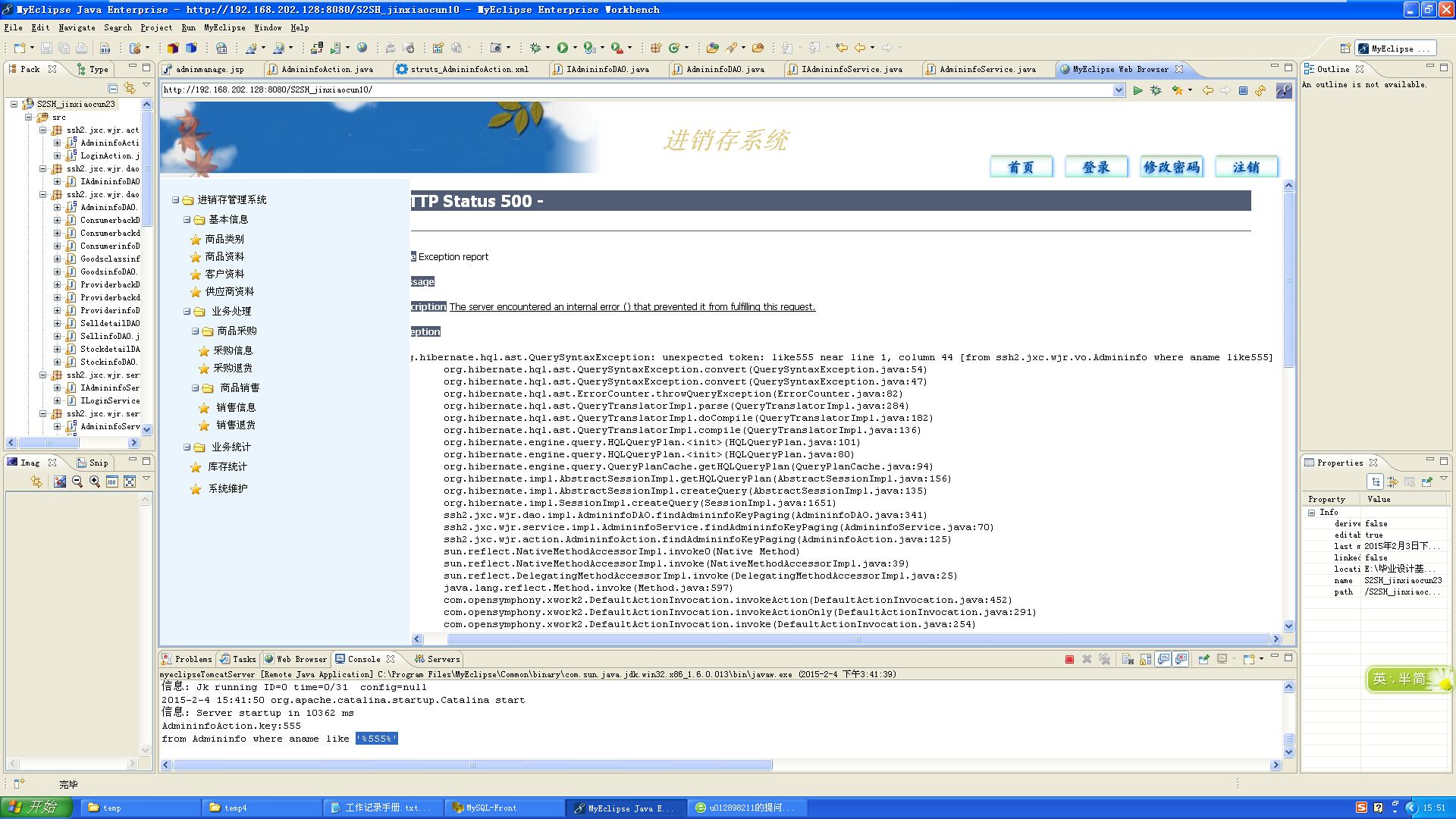
关注like后面要加空格,像 " select * from user where name like '% "+ key +"%' "
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
分享
- 2020-12-21 19:35weixin_39612058的博客 Hibernate HQL查询:Criteria查询对查询条件进行了面向对象封装,符合编程人员的思维方式,不过HQL(Hibernate Query Lanaguage)查询提供了更加丰富的和灵活的查询特性,因此Hibernate将HQL查询方式立为官方推荐的...
- 2021-01-27 00:20shanyitattoo的博客 本章介绍了Hibernate的几种主要检索方式:HQL检索方式、QBC检索方式、SQL检索方式。HQL是...Hibernate是一个轻量级的框架,它允许使用原始SQL语句查询数据库。1.1HQL基础HQL是Hiberante官方推荐的...
- 2019-06-02 21:55Mr_tz的博客 什么是HQL呢? HQL是Hibernate Query Language的缩写,提供更加...完整的HQL语句形势如下: Select/update/delete…… from …… where …… group by …… having …… order by …… asc/desc 非常类似标准的S...
- 2022-07-03 19:24满眼凄迷i的博客 本文主要内容 1.HQL查询语句与MySQL执行顺序的区别; 2.Hive复合类型的数据查询、正则查询...7.Hive调优分为环境调优和HQL语句调优; 8.Hive总结与扩展explode函数和lateral 虚拟表的用法。........................
- 2020-09-06 20:38闻香识代码的博客 HQL(Hive SQL) 之查询语句专题汇总 1. 背景 hive本身是一个将sql语句转换为mapreduce 程序运行的转换器 hive可以把结构化数据转换到一张表上,并提供查询和分析的功能 针对这个过程,hive从sql优化、从mapreduce...
- 2017-04-14 16:42Hacker天使马晓培的博客 原文地址:hql语句的语法作者:毛义法 一、HQL查询的from子句 from是最简单的语句,也是最基本的HQL语句。from关键字后紧跟持久化类的类名。 例如: from Person 表明从Person持久化类中选出全部的实例 ...
- 2020-08-11 19:39进击的斐的博客 HQL(Hive Query Language) 常用数据类型:int 、string 常用语句 查询数据库: show databases 创建数据库: create database [ if not exists ] mydb 显示数据库信息: desc database mydb 显示数据库详细信息: ...
- 2024-01-06 21:36之宇不咸的博客 HQL 中DDL语句理解
- 2022-07-03 20:13红目香薰的博客 目录Hive基础08、HQL查询语句1、基础查询语句2、数组查询3、map4、struct5、聚合查询语句HQL查询内容全:第一部分:Hive查询语句Hive函数1. 聚合函数2. 关系运算3. 数学运算4. 逻辑运算5. 数值运算6. 条件函数7. ...
- 2021-03-15 11:49weixin_39997253的博客 本讲要点:l Hibernate数据查询l 利用关联关系操纵对象l Hibernate事务l Hibernate的Cache管理9.1 Hibernate数据查询数据查询与检索是Hibernate的一个亮点。Hibernate的数据查询方式主要有3种,它们是:l Hibernate ...
- 没有解决我的问题, 去提问
