Eclipse 安装Hadoop2.6插件,配置Map/Reduce Location后,配置如图: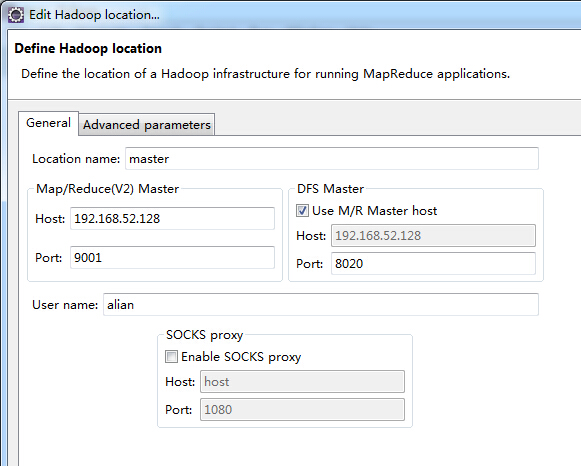 报错
报错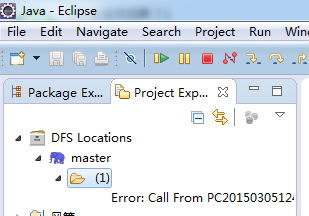 报错详情:Error:Call From PC201503051247/192.168.6.240 to 192.168.52.128:8020 failed on connection exception: java.net.ConnectException: Connection refused: no further information
报错详情:Error:Call From PC201503051247/192.168.6.240 to 192.168.52.128:8020 failed on connection exception: java.net.ConnectException: Connection refused: no further information

Eclipse 安装Hadoop2.6插件

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新

- 2018-11-18 21:355. **安装与使用**:下载名为"hadoop2x-eclipse-plugin-2.6.0"的压缩包后,按照Eclipse的插件安装指南进行操作,通常涉及解压、复制到Eclipse的plugins目录,然后重启Eclipse。一旦安装成功,开发者就可以在Eclipse...
- 2017-11-03 11:21本文将深入探讨Hadoop 2.6版本的WinUtils插件及其相关的Eclipse插件,这对于Windows环境下的Hadoop开发者至关重要。 首先,让我们理解什么是WinUtils。在Linux环境下,Hadoop通常与`hadoop`命令行工具一起工作,但...
- 2018-01-07 18:52标题提到的"hadoop2.6 eclipse 插件"正是这种插件的一个版本,适用于Hadoop 2.6和Windows 7操作系统。在Windows 7环境下进行Hadoop开发,使用Eclipse插件可以简化配置过程,减少手动设置Hadoop环境的复杂性。 描述...
- 2015-04-02 12:34Eclipse是一个流行的Java集成开发环境,通过安装特定插件,可以支持Hadoop开发。 标题中提到的关键是"win7下eclipse配置hadoop的插件",这意味着我们要在Windows 7操作系统上,利用Eclipse进行Hadoop开发的环境配置...
- 2019-10-20 15:57PhdanSong的博客 eclipse中hadoop插件出不来解决办法: cmd进入到eclipse.exe所在的位置,输入“exlipse.exe -clean”命令,重启即可 1、jdk环境配置 正常步骤,略 2、eclipse环境配置 正常步骤,略 3、下载hadoop-2.6.0.t...
- 2021-02-27 14:07杜晓斑的博客 Windows10(64位)中Eclipse Luna Service Release 2 (4.4.2 64位)中Hadoop2.6.0配置1 系统配置Windows10(64位)Eclipse Luna Service Release 2 (4.4.2 64位)Hadoop2.6.0JDK1.8.0(64位)SVN1.8.6ANT1.9.62 Eclipse和...
- 2017-12-22 16:28在提供的压缩包`hadoop2.6-eclipse`中,可能包含了专门为Eclipse集成的Hadoop 2.6配置文件和库,这将简化Windows上的开发环境设置。解压后,按照上述步骤进行配置,可以加快开发过程并减少潜在问题。记得始终检查...
- 2018-03-21 23:54言析数智的博客 完成eclipse + hadoop2.6.x 开发环境搭建 ; 常见错误总结 ; 大数据等综合技术积累 . 环境搭建 推荐参考文章 (已比较全面,不在赘述) 搭建Hadoop2.6.0+Eclipse开发调试环境 问题总结 (重点) 问题 1 ...
- 2015-01-24 21:21hadoop-eclipse-plugin-2.6.0.jar windows8 x64下用eclipse开发hadoop2.6.0的程序 编译环境: java:1.8.20 eclipse: Version: Luna Service Release 1a (4.4.1) Build id: 20150109-0600 正常使用
- 2018-05-27 18:113. **安装插件**: 在Eclipse中安装Hadoop相关的插件,如Hadoop插件(如Hadoop Eclipse Plugin)和CDH Plugin,这些插件可以帮助开发者将Hadoop项目集成到IDE中,便于创建、编辑和运行Hadoop作业。 4. **配置Hadoop*...
- 没有解决我的问题, 去提问

