hadoop2.6使用snappy.报错native snappy library not available: this version of libhadoop was built without snappy support.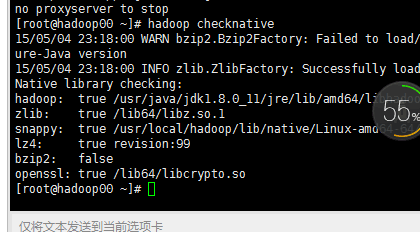
hadoop里面明明已经显示启用了snappy

hadoop2.6使用snappy.报错

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

0条回答 默认 最新
- 2024-09-18 10:39编码人生_的博客 所有的元数据会先存储在内存上文件信息,datanode信息,块信息元数据文件为了避免内存上的元数据丢失,会将内存的上的元数据保存在磁盘上secondarynamenode完成元数据文件的保存存储位置在hadoop的指定数据edits_...
- 2020-06-23 00:34programmer_trip的博客 目录环境:问题:问题解决流程 环境: 操作系统:Windows10> hadoop : hadoop 2.7.6> IDE : idea 2020.1>...在idea中使用hadoop本地模式运行一个mapreduce任务,抛出如下异常: Exception in thread "mai
- 2023-02-20 12:33huan_1993的博客 最近在学习`hadoop`,此篇文章简单记录一下通过源码来编译`hadoop`。为什么要重新编译`hadoop源码`,是因为为了匹配不同操作系统的本地库环境。
- 2025-05-20 15:39#0000Rr的博客 本文档详细介绍了Hadoop的核心概念、优势及组件(HDFS、YARN、MapReduce),并提供了从零搭建Hadoop集群的完整指南,包括节点规划、环境配置、SSH免密登录、集群启动及验证。通过浏览器访问和配置历史服务器,确保...
- 2022-08-28 09:37m0_67401761的博客 然后打开最近一次启动时间的日志文件。可知,是配置etc/hadoop/hdfs-site.xml 的dfs.http.address...所以我将下面的hadoop-hadoop-namenode-hadoop.fang.com.log复制到我的windows共享文件夹下,来查看日志文件。...
- 2024-04-05 14:31SparklingTheo的博客 文章目录 1 错误复现 2 错误分析 3 解决方法 1 错误复现 hive cli读取parquet格式存储表格时报错 ERROR:in thread "main" org.xerial.snappy.SnappyError: [FAILED_TO_LOAD_NATIVE_LIBRARY] null 深入阅读报错信息...
- 2024-01-04 18:56之乎者也·的博客 hadoop中HDFS要存储数据,这些数据存储的目录地址,默认值为:/tmp/hadoop-${user.name},如下图2所示为默认值,在本环境 Linux系统里面是指:/tmp/hadoop-zola,但是 /tmp 目录是1个临时目录,一般Linux系统1个月...
- 2021-10-12 21:15Lowrance_TT的博客 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。 本质是:将HQL转化成MapReduce程序 Hive处理的数据存储在HDFS Hive分析数据底层的实现是MapReduce 执行程序运行...
- 2020-09-26 20:36m0_51100209的博客 本文着重分解Hadoop理论基础及底层原理 文中涉及的Hadoop是基于2.x版本(2.9) 1. 大数据 1.1 定义 无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合 需要新处理模式才能具有更强的决策力、...
- 2024-08-22 11:35jeady82的博客 大数据hbase2.6 on hadoop3 安装部署
- 没有解决我的问题, 去提问
