1、conf文件如下
agent1.sources = source1
agent1.channels = channel1
agent1.sinks = snik1
# source
agent1.sources.source1.type = avro
agent1.sources.source1.bind = nnode
agent1.sources.source1.port = 44446
agent1.sources.source1.threads = 5
# channel
agent1.channels.channel1.type = memory
agent1.channels.channel1.capacity = 100000
agent1.channels.channel1.transactionCapacity = 1000
agent1.channels.channel1.keep-alive = 30
agent1.channels.channel1.byteCapacityBufferPercentage = 20
# agent1.channels.channel1.byteCapacity = 200M
# sink
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /flume/
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.filePrefix = event_%y-%m-%d_%H_%M_%S
agent1.sinks.sink1.hdfs.fileSuffix = .log
agent1.sinks.sink1.hdfs.writeFormat = Text
agent1.sinks.sink1.hdfs.rollInterval = 30
agent1.sinks.sink1.hdfs.rollSize = 1024
agent1.sinks.sink1.hdfs.rollCount = 0
agent1.sinks.sink1.hdfs.idleTimeout = 20
agent1.sinks.sink1.hdfs.batchSize = 100
#
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
2、hdfs集群为hdfs://cluster,两个namenode节点分别为:nnode、dnode1
3、java代码
package com.invic.hdfs;
import java.io.IOException;
import java.util.Arrays;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.apache.hadoop.fs.permission.FsAction;
import org.apache.hadoop.fs.permission.FsPermission;
import org.apache.log4j.Logger;
/**
*
* @author lucl
*
*/
public class MyHdfs {
public static void main(String[] args) throws IOException {
System.setProperty("hadoop.home.dir", "E:\\Hadoop\\hadoop-2.6.0\\hadoop-2.6.0\\");
Logger logger = Logger.getLogger(MyHdfs.class);
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://cluster");
conf.set("dfs.nameservices", "cluster");
conf.set("dfs.ha.namenodes.cluster", "nn1,nn2");
conf.set("dfs.namenode.rpc-address.cluster.nn1", "nnode:8020");
conf.set("dfs.namenode.rpc-address.cluster.nn2", "dnode1:8020");
conf.set("dfs.client.failover.proxy.provider.cluster", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
for (int i = 0; i < 500; i++) {
String str = "the sequence is " + i;
logger.info(str);
}
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.exit(0);
}
}
4、log4j
log4j.rootLogger=info,stdout,flume
### stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
### flume
log4j.appender.flume=org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.layout=org.apache.log4j.PatternLayout
log4j.appender.flume.Hostname=nnode
log4j.appender.flume.Port=44446
log4j.appender.flume.UnsafeMode=true
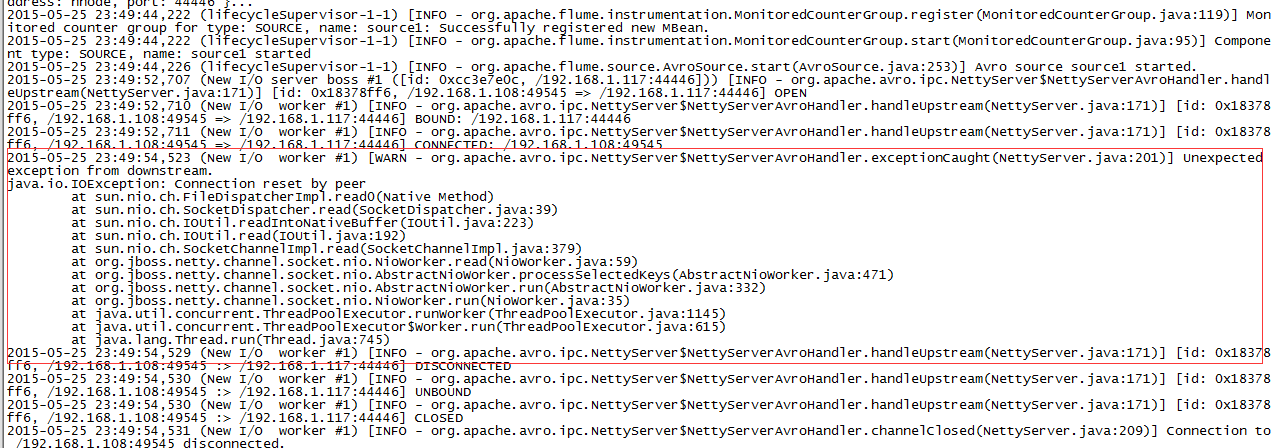
5、执行结果