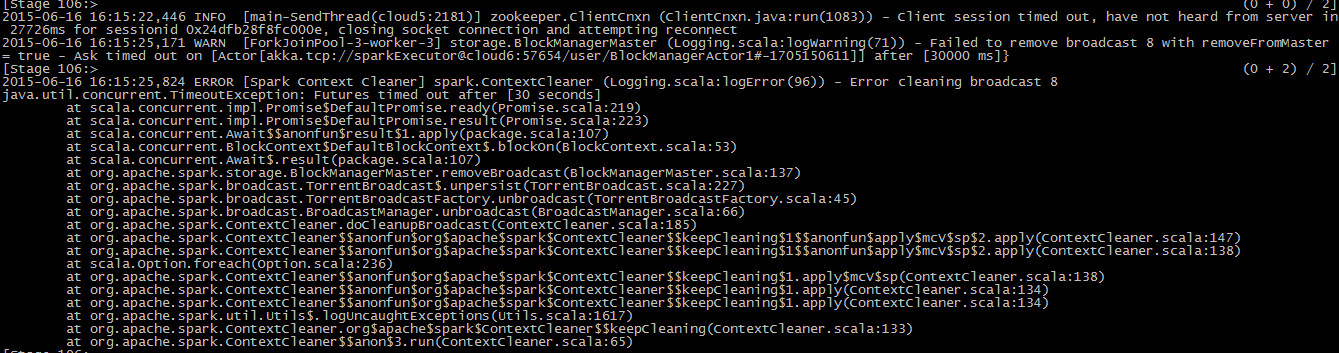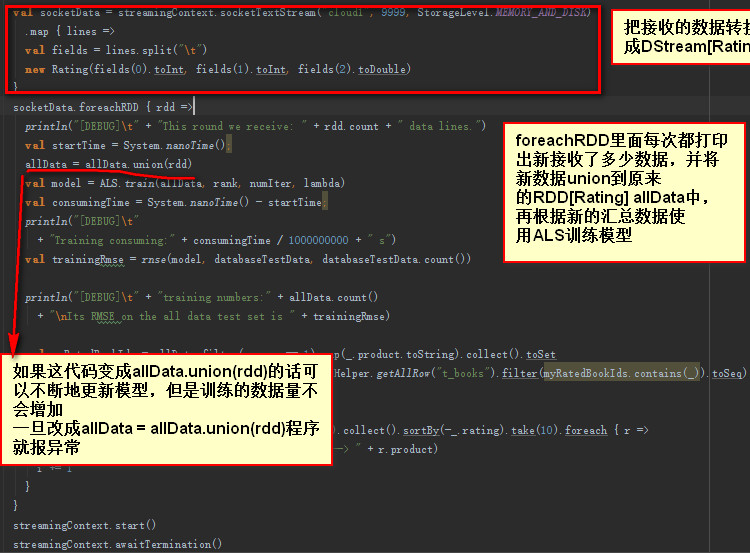


在spark streaming中使用ALS算法,实现模型的实时更新有人了解吗?
总是出ERROR [dag-scheduler-event-loop] scheduler.DAGSchedulerEventProcessLoop (Logging.scala:logError(96)) - DAGSchedulerEventProcessLoop failed; shutting down SparkContext
这个异常是什么意思?网上找了好久都没解决。。快疯了
大概就是上面几张图描述的那样子,求教育!