直接在浏览器中访问
用PHP中的curl访问后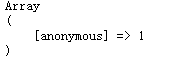 ,为甚么两次的不一样??
,为甚么两次的不一样??

PHP 中用curl访问一个页面和直接在浏览器中直接访问这个页面为什么两次的返回值不一样?

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


3条回答 默认 最新

- 2017-03-20 23:05回答 1 已采纳 Fox News appears to be blocking access to their website from any request passing a USERAGENT. Simp
- 2022-04-26 11:58回答 1 已采纳 格式不一样,把请求头的Content-type改成application/json ,就可以了
- 2017-03-17 12:30回答 1 已采纳 Replace return "ok"; With echo "ok"; Your script is exiting with return value, but nothing
- 2022-07-11 07:38「已注销」的博客 From:http://www.jb51.net/LINUXjishu/86326.html From :Linux curl 命令详解 - http://www.cnblogs.com/duhuo/p/5695256.html Linux curl 命令参数详解:http://www.aiezu.com/system/linux/linux_curl...
- 2019-04-01 16:29回答 2 已采纳 在前一个页面内容里加这个 <input name="num" valus="地址参数" type="hidden" 然后url这样就行了 https://wdbible.com/api/b
- 2017-02-28 13:54回答 1 已采纳 try this one to view your link image contents <?php header("Content-Type: image/jpeg"); $url
- 2018-05-16 06:30回答 2 已采纳 curl获取的是源代码,就是你邮件查看源代码,得到什么就是什么,js动态解析的内容是获取不到的,要获取js动态解析添加的内容,需要用webbrowser之类的window组件或者用谷歌chrome v
- 2021-04-11 12:23酥牧奇的博客 这是一个适合阅读的系列,我希望您能够在车上、厕所、餐厅都阅读它,涉及代码的部分也是精简而实用的。学习需要动机Go语言能干什么?为什么要学习Go语言?本系列文章,将会以编程开发中需求最大、应用最广的Web开发...
- 2021-08-02 16:03回答 2 已采纳 你访问的是同一个url?你爬取的是列表内容。并没有去请求详细内容
- 2017-06-27 02:16回答 1 已采纳 maybe answered on How to use basic authorization in PHP curl so try from that: <?php $username
- 2019-05-20 12:28回答 1 已采纳 Something like this should do it, there are a lot of post on using cUrl with PHP How to POST JSO
- 2020-03-02 16:04八重樱。的博客 1.什么事面向对象?主要特征是什么? 面向对象是程序的一种设计方式,它利于提高...1、http无状态协议,不能区分用户是否是从同一个网站上来的,同一个用户请求不同的页面不能看做是同一个用户。 2、SESSION存储...
- 2016-11-30 23:22回答 1 已采纳 The underlying CURLOPT_CAINFO option in libcurl only supports a single file name, and PHP/CURL mer
- 2021-11-14 15:26而立了吗?的博客 如果是在全局环境中引入一个文件,那这个文件是可以直接访问全局变量的。如果在局部作用域(函数内)引入文件, 那这个引入的作用域也是局部的。 那如果在一次请求中,所有用到的文件都是通过require串联在一起的。...
- 2023-03-13 18:55牛马。。。的博客 } } 测试运行通过访问localhost:8080/hello浏览器输出hello,world 2.2.4、项目打jar包 点击maven里的package 在target会得到一个jar包 执行命令:java -jar .\demo-0.0.1-SNAPSHOT.jar 测试在浏览器访问...
- 2022-10-28 19:14我是你的小阿磊的博客 复习php的一些笔记
- 2022-04-07 15:18知白守黑V的博客 那么,常见的能够触发这类漏洞的函数有哪些呢? eval()# 想必大家对eval()函数应该并不陌生,简而言之eval()函数就是将传入的字符串当作 PHP 代码来进行执行。 eval( string $code) : mixed 返回值# eval() 返回 ...
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 素材场景中光线烘焙后灯光失效
- ¥15 请教一下各位,为什么我这个没有实现模拟点击
- ¥15 执行 virtuoso 命令后,界面没有,cadence 启动不起来
- ¥50 comfyui下连接animatediff节点生成视频质量非常差的原因
- ¥20 有关区间dp的问题求解
- ¥15 多电路系统共用电源的串扰问题
- ¥15 slam rangenet++配置
- ¥15 有没有研究水声通信方面的帮我改俩matlab代码
- ¥15 ubuntu子系统密码忘记
- ¥15 保护模式-系统加载-段寄存器