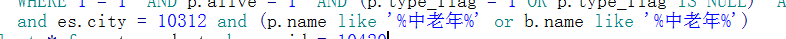
我想用lucene的BooleanQuery写出这种类型的条件

关于lucene的多条件查询问题

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
- IsResultXaL 2015-08-31 10:02关注
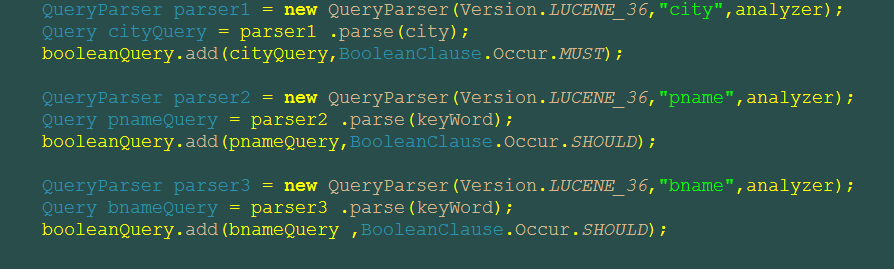
我现在这么写的效果是and es.city=10312 or p.name like'%?%' or b.name like '%?%'本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2019-07-27 02:55总的来说,Lucene的多字段查询和文字高亮显示是提高用户体验和增强搜索功能的关键技术。它们使得用户能够更快地找到相关信息,并且更直观地看到搜索结果中的关键匹配点。通过深入学习和实践,你可以在自己的项目中...
- 2020-03-25 13:44三天打鱼_的博客 lucene多条件查询 使用booleanQuery进行组合 特点是使用查询关键词已经是最小分词单元,不需要分词 booleanQuery本身是一个布尔子句的容器,可以将lucene提供的Query子类添加到其中,标明子句之间的关系,组合条件后...
- 2020-12-28 11:17以上就是关于“lucene创建修改删除组合条件查询”的主要知识点。通过熟练掌握这些操作,开发者可以构建出强大的全文搜索系统,满足各种复杂的查询需求。在实际应用中,还需要注意性能优化,如合理使用索引,以及根据...
- 2018-08-05 20:14总之,Lucene在C#中的时间区间搜索是通过构建和执行RangeQuery来实现的,这涉及到索引构建、查询解析、时间值的转换和比较等多个环节。合理地利用这些技术,可以有效地提升数据检索的效率和准确性。在实际应用中,还...
- 2022-06-06 10:40这些工具在Lucene的基础上添加了更多管理和扩展功能,使搜索解决方案更加完整。 对于开发语言,Java是Lucene的主要实现语言,这意味着所有的API和类都是用Java编写。如果你熟悉Java,那么使用Lucene会非常方便。...
- 2024-05-30 11:59Yz_w的博客 3.Boolean Queries : 多条件并列查询,使用布尔逻辑组合多个查询条件。8.Filtered Queries : 过滤查询,结合一个查询和一个过滤条件。Lunece提供了丰富的查询方式来满足检索需要,以下是一些常用的查询方式。5....
- 2022-09-14 22:29**Lucene搜索引擎简介** Lucene是一个高性能、全文检索库,由Apache软件基金会开发并维护,是Java...在实际应用中,可能还需要考虑性能优化、多语言支持、实时索引更新等问题,以提供更高效、准确和便捷的搜索体验。
- 2020-08-28 11:09"Lucene实现索引和查询的实例讲解" Lucene是一种基于Java的全文检索引擎工具包,提供了丰富的API,方便开发人员在目标系统中实现全文检索的功能。Lucene的结构设计与数据库的设计较为相似,但Lucene的索引与数据库...
- 2020-09-13 16:46- **多字段搜索**:允许用户在多个字段中同时进行搜索,提高查询的灵活性。 在实际应用中,可能还需要考虑如何处理停用词、同义词、词形还原等问题,以提升搜索质量。此外,定期重建索引和优化索引结构也是保持搜索...
- 2026-01-03 11:07分词处理是为了使Lucene能够精确识别时间值,并据此与查询条件进行比对。 时间区间查询的核心在于构建合适的Query对象。 Lucene提供了多种查询模式,例如TermQuery、PrefixQuery、RangeQuery等不同类型。 在时间范围...
- 没有解决我的问题, 去提问

