FileInputStream 的无参read()方法,每次读到的是一个字节,那他返回给的int变量的是一个字节的int表现形式,还是一个基本数据(如char字符数据)的字节值的int表现形式?如果是返回的一个字节,那这个字节转化成的int值,最多只能取到2的8次方即255个,单个字节是无法表示一个字符的,如果原文件中有汉子,系统又是怎么样把一个字节的数据转换成汉子呢?本人新手,这块不是很理解,求大神解答,谢谢!

java中的字节输入流的无参read方法,每次读到的是一个字节,还是一个基本数据的字节值?

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


3条回答 默认 最新

 关注
关注字节的数据转换成汉子,先以字节读,再以字符转换
InputStreamReader isr = new InputStreamReader(new FileInputStream(file), "UTF-8");解决 无用评论 打赏举报 分享
- 2022-03-29 09:04回答 2 已采纳 第二个不行,是因为你只读取了1024个字节长度。而且只读取了一次。
- 2021-10-31 20:56回答 3 已采纳 这个问题问的很有意思,一般好学的初学者都有这种困惑。 为啥【java为什么字节输入流用FileInputStream的read,做的是输出】? 初学者一般认为:【字节从A文件流向B文件,那么就认为数据
- 2021-11-06 20:00回答 1 已采纳 删除第11行的代码,哪行代码是错误的。把Byte改为byte即可。 FileOutputStream fos = new FileOutputStream("文件名称",true); byt
- 2020-09-23 20:12云深i不知处的博客 什么是Java-IO?字符流和字节流的区别与适用场景是什么?缓冲流到底实现了什么?如何高效地读写文件? 本文用大量的示例图和实例,带你吃透Java IO。
- 2022-09-05 18:39回答 1 已采纳 byte[] bytes = new byte[5]; //一次读取x个字节 int length ; while ((length = fis.read(bytes)
- 2016-12-08 11:11回答 3 已采纳 你代码写的基本上没问题,就是一个小地方没有注意到 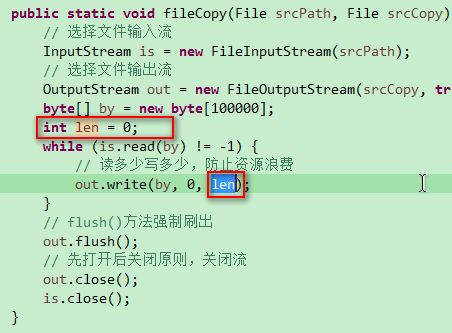
- 2022-04-02 13:04回答 1 已采纳 要保证 java.txt 文件使用 GBK 编码存储才能用 GBK 编码读取,否则就会乱码,如果你不确定编码类型的话可以改成 UTF-8 试试看,这个编码用的比较多。
- 2021-02-26 15:39爱文斯坦的博客 1.读取字节流FileInputStream中的全部字节package IO;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.IOException;import java.io.InputStream;public ...
- 2021-10-23 15:04回答 1 已采纳 FileInputStream inputStream = null; FileInputStream in = null; //创建输入流对象
- 2022-07-29 01:16回答 2 已采纳 我觉得一个很简单的做法是,在客户端就识别出类型,传输的时候把文件类型一起带给你
- 2020-08-16 18:01回答 1 已采纳 https://www.cnblogs.com/xxbai1123/p/9264384.html 在这个程序基础上加上读取文本文件即可。
- 2019-05-20 08:46一JJL的博客 package ... import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.io.OutputStream; public class ByteStream...
- 2022-12-12 23:01回答 2 已采纳 将你路径路面的斜杠“\” 改为反斜杠即可“/” ,因为java中的很多转义都是通过斜杠\来转义的,所以一般路径尽量避免使用\,使用的时候也注意要转义一下也就是使用 双斜杠 \\你这个是因为读取配置文件
- 2021-03-07 19:46NaiQai的博客 在java的io编程中,读取文件是分为两个步骤的 1.将文件中的数据转换为流对象 2.读取流对象的数据 具体步骤 1.创建流对象 2.读取流对象内部的数据 3.关闭流对象 以下是具体代码,包含注释 public static void ...
- 2022-08-05 08:00SSS4362的博客 解析java中的文件字节输入流
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 R语言Rstudio突然无法启动
- ¥15 关于#matlab#的问题:提取2个图像的变量作为另外一个图像像元的移动量,计算新的位置创建新的图像并提取第二个图像的变量到新的图像
- ¥15 改算法,照着压缩包里边,参考其他代码封装的格式 写到main函数里
- ¥15 用windows做服务的同志有吗
- ¥60 求一个简单的网页(标签-安全|关键词-上传)
- ¥35 lstm时间序列共享单车预测,loss值优化,参数优化算法
- ¥15 Python中的request,如何使用ssr节点,通过代理requests网页。本人在泰国,需要用大陆ip才能玩网页游戏,合法合规。
- ¥100 为什么这个恒流源电路不能恒流?
- ¥15 有偿求跨组件数据流路径图
- ¥15 写一个方法checkPerson,入参实体类Person,出参布尔值