
SELECT date_format(createTime,'%Y-%m-%d') createTime
from t_zx_sqzx
where communityId='8' GROUP BY date_format(createTime,'%Y-%m-%d')
DESC
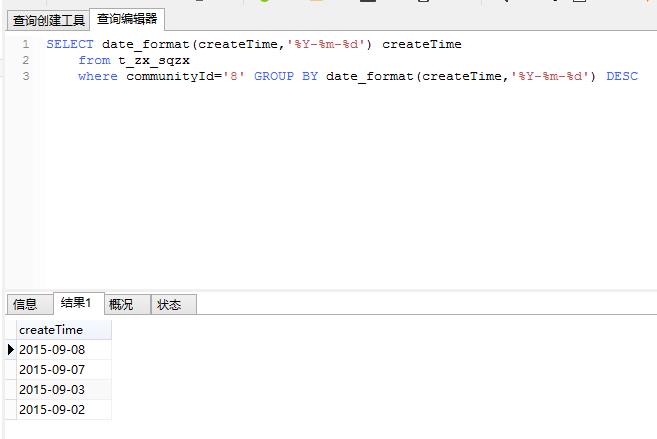
这是从数据库读取出的数据,怎么取第2第3条数据,或者其他条数据







