
恳请大佬给个指导~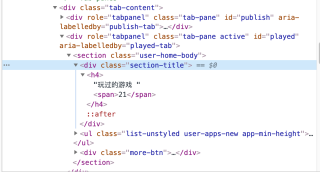


2条回答 默认 最新
 戴上微笑 2020-11-30 14:04关注
戴上微笑 2020-11-30 14:04关注直接右键span位置选择copy在选择copy Xpath 获得路径之后后面再加text()
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
分享
- 2025-04-02 11:27总结而言,Python爬取网站图片的过程涉及到网络请求的发送、HTML内容的解析、图片资源的提取以及本地存储等关键步骤。掌握这些基础知识,配合各种工具库的使用,可以有效地完成对网站图片资源的自动化采集工作。在此...
- 2025-08-22 12:00使用Python爬取链家网站的示例代码,不仅可以帮助我们收集到丰富的房地产市场数据,而且通过实际操作,我们可以学习到网络爬虫技术在实际应用中的具体实现方法,并能够通过数据分析对市场趋势做出一定的预测和判断。...
- 2020-05-07 17:02「已注销」的博客 如何用python爬取异步加载的网页?以京东商品评论为例。 在用python爬取网页时,会遇到网页不是一次性全部加载的情况,这种网页会在某种操作后,才加载对应的部分,拿京东来说,点进商品页面,并不会直接加载评论...
- 2024-11-26 19:33LucianaiB的博客 深入解析:使用Python爬取Bilibili视频
- 2020-09-20 10:13Python爬虫用于爬取静态网页图片的方法涉及到网络爬虫的基本原理和Python的相关库。首先,爬虫的主要步骤包括下载网页、管理URL以及解析网页内容。在Python中,我们可以使用内置的`urllib2`或第三方库`requests`作为...
- 2020-09-19 13:10Python爬取实时变化的WebSocket数据是一项技术性强且实用的任务,主要应用于实时数据抓取,例如体育赛事、股市或数字货币市场的动态信息。WebSocket协议是HTTP协议的升级版,它提供了全双工通信,允许服务器主动向...
- 2025-11-12 15:40使用Python将数据存储到MySQL数据库中,需要借助数据库操作库,比如mysql-connector-python。通过这些库,可以实现数据的创建、读取、更新和删除操作。将爬取到的数据保存到数据库中,不仅方便了数据的整理和查询,...
- 2025-11-15 06:30本文将详细介绍使用Python语言如何实现对B站视频内容的爬取。首先,开发者可以利用浏览器的开发者工具来分析B站网页的网络请求,从而找到视频和音频文件的直接下载链接。这一过程通常涉及到对请求头信息的详细查看,...
- 2022-03-01 17:27呜昂王0521的博客 文章目录前言一、使用python爬取网上数据并写入到excel中例子一:例子二:二、工具类总结 前言 记录一下使用python将网页上的数据写入到excel中 一、使用python爬取网上数据并写入到excel中 要爬取数据的网站: ...
- 2025-11-13 07:48本教程致力于向对App数据爬取感兴趣的读者展示如何使用Python语言,结合Fiddler抓包工具,对iOS系统上的App进行数据爬取和分析。 首先,教程会指导读者如何安装并配置Fiddler工具,这是网络抓包分析的重要工具,...
- 没有解决我的问题, 去提问

