
最近在用Mapreduce连Hadoop,出现各类问题。请高手答疑。
环境:
hadoop:2.7.0
Hbase:1.0.1.1
刚开始的时候报:HBaseConfiguration 找不到,百度之,说将 hbase的lib下的jar复制到hadoop的lib下
复制之,无果,找各类参考资料修改hadoop参数,都还是报异常。
最后无奈,只能修改 hadoop-env.sh,将 hbase 的lib加入到 classpath下。
最后终于不报这个异常。
可是接着更加无解的事情发生了。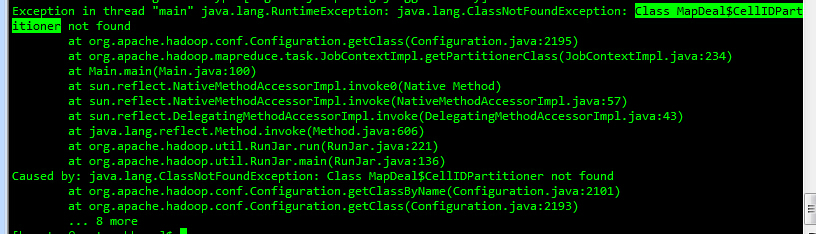
报出各类我自己定义的类找不到。
网上找遍了所有的贴,没找到答案。
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
conf = HBaseConfiguration.create(conf);
if (args.length != 6)
{
System.err.println("Usage: MroFormat <in-mro> <in-xdr> <sample tbname> <event tbname>");
System.exit(2);
}
//makeConfig(conf, args);
String inpath1 = args[0];
String inpath2 = args[1];
Job job = Job.getInstance(conf,"MyTest");
job.setNumReduceTasks(40);
job.setJarByClass(Main.class);
job.setReducerClass(ReduceDeal.MroFormatReducer.class);
//job.setReducerClass(ReduceDeal.TestReducer.class);
job.setSortComparatorClass(MapDeal.SortKeyComparator.class);
job.setPartitionerClass(MapDeal.CellIDPartitioner.class);
job.setGroupingComparatorClass(MapDeal.SortKeyGroupComparator.class);
job.setMapOutputKeyClass(CellTimeKeyPare.class);
job.setMapOutputValueClass(Text.class);
MultipleInputs.addInputPath(job, new Path(inpath1), KeyValueTextInputFormat.class, MapDeal.MroMapper.class);
MultipleInputs.addInputPath(job, new Path(inpath2), TextInputFormat.class, MapDeal.XdrMapper.class);
job.setOutputFormatClass(MultiTableOutputFormat.class);
//job.setOutputFormatClass(NullOutputFormat.class);
//LOG.info(job.getPartitionerClass().getName());
//TableMapReduceUtil.addDependencyJars(job);
//TableMapReduceUtil.addDependencyJars(job.getConfiguration());
//TableMapReduceUtil.initTableReducerJob("tab1", ReduceDeal.MroFormatReducer.class, job);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
在本机的win7环境下,代码能跑过,但打包放到服务器就报错,找不着类。去掉了“conf = HBaseConfiguration.create(conf);”这段代码后,下面的 处理类就可以找到。请大牛们帮忙看看,非常感谢






