http://weixin.sogou.com/weixin?query=AECOM&fr=sgsearch&type=2&ie=utf8&w=01019900&sut=3992&sst0=1442279218592&lkt=4%2C1442279216085%2C1442279217157
这十个列表页面,我想知道每条新闻的真实链接,因为重定向过,不知道怎么写,求大神指导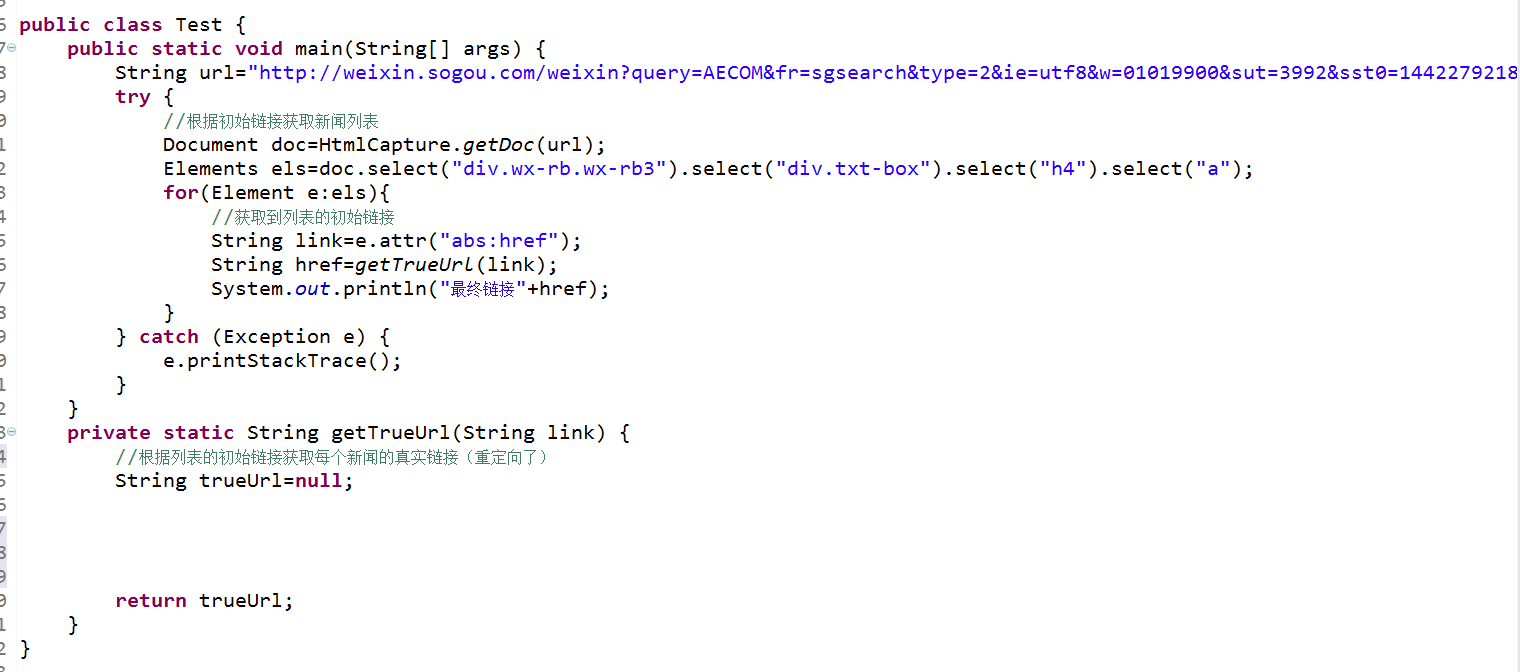

关于java网络爬虫遇到重定向的情况

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
 你知我知皆知 2024-08-04 08:41关注
你知我知皆知 2024-08-04 08:41关注以下回答参考 皆我百晓生、券券喵儿 等免费微信小程序相关内容作答,并由本人整理回复。
要解决这个问题,你需要使用Java的
HttpClient和HttpURLConnection来处理HTTP请求。以下是一个基本的示例,展示了如何从一个网页中提取新闻列表,并尝试获取每个新闻的真实链接。首先,确保你的项目中已经包含了
HttpClient和HttpURLConnection的依赖。如果你在使用Maven,可以在pom.xml文件中添加以下依赖:<dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.12</version> </dependency>然后,你可以使用以下代码来获取新闻列表并获取真实链接:
import org.apache.http.HttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.DefaultHttpClient; import java.io.IOException; import java.util.ArrayList; import java.util.List; public class Main { public static void main(String[] args) throws IOException { String url = "http://weixin.sogou.com/weixin?query=AECOM&fr=sgsearch&type=2&ie=utf8&w=01019900&sut=3992&sst0=1442279218592&lkt=4%2C1442279216085%2C1442279217157"; DefaultHttpClient httpClient = new DefaultHttpClient(); HttpGet httpGet = new HttpGet(url); HttpResponse response = httpClient.execute(httpGet); // 读取响应正文 try (InputStream in = response.getEntity().getContent()) { Document document = Jsoup.parse(in, "UTF-8"); Elements elements = document.select("div.wx-rb.wx-rb3"); List<String> links = new ArrayList<>(); for (Element element : elements) { Element h4 = element.selectFirst("h4"); String link = h4.selectFirst("a").attr("abs:href"); links.add(link); } System.out.println(links); } finally { httpClient.getConnectionManager().shutdown(); } } }这个代码首先发送一个GET请求到给定的URL。然后,它解析返回的HTML文档,并从中提取出所有包含标题的
<h4>元素。对于每个标题,它都试图找到相应的超链接,并将其存储在一个列表中。注意:这只是一个基本的示例,实际操作可能需要根据你具体的需求进行调整。例如,你可能需要处理重定向、错误状态码或其他异常情况。此外,为了安全起见,请不要直接访问用户输入的内容,而是应该将这些内容包装起来,以防止SQL注入等攻击。
解决 无用评论 打赏举报 分享
- 2024-03-29 21:22下面是一段关于Java网络爬虫源码资源的描述: 这段Java网络爬虫源码资源是一个功能完善且易于扩展的爬虫框架。它采用了模块化设计,使得用户可以轻松地根据自己的需求进行定制和扩展。源码中包含了网络请求模块、...
- 2021-03-15 00:26南宫寒风的博客 1.服务器端重定向,在服务器端完成,一般来说爬虫可以自适应,是不需要特别处理的,如响应代码301(永久重定向)、302(暂时重定向)等。具体来说,可以通过requests请求得到的response对象中的url、status_code两个属性...
- 2023-07-13 19:5010. **爬虫框架**:有些项目可能使用现成的Java爬虫框架,如WebMagic、Colly、JsoupCrawler等,它们提供了开箱即用的功能和更高级的抽象。 这个"Java网络爬虫源码"很可能包含了以上部分或全部的实现。通过研究源码...
- 2024-04-10 10:205. **爬虫框架**:虽然这个项目提供的是源码,但值得一提的是,有些成熟的Java爬虫框架,如WebMagic、Colly,可以简化爬虫开发流程。 6. **IP代理和反爬策略**:为了避免被目标网站封禁,网络爬虫可能需要使用IP...
- 2021-03-15 00:25浔阳咸鱼的博客 笔者编写的搜索引擎爬虫在爬取页面时遇到了网页被重定向的状况,所谓重定向(Redirect)就是经过各类方法(本文提到的为3种)将各类网络请求从新转到其它位置(URL)。每一个网站主页是网站资源的入口,当重定向发生在网站...
- 2024-05-05 10:17在本项目中,我们主要探讨的是一个基于Java编程语言实现的网络爬虫程序。网络爬虫,也称为网页抓取器或蜘蛛,是自动化浏览互联网并下载网页的程序。它通常用于数据挖掘、搜索引擎索引更新以及各种数据分析任务。在这...
- 2023-07-02 22:55本项目源码提供了一种实现Java爬虫的方法,适用于学习、毕业设计或者作为开发工具。 在Java中实现网络爬虫涉及的主要技术点包括: 1. **HTTP请求库**:Java提供了多种库如HttpURLConnection(Java内置)、Apache ...
- 2024-06-21 10:24在编程领域,尤其是在数据挖掘和大数据分析中,Java爬虫是至关重要的工具。本资源包"搜索链接Java网络爬虫(蜘蛛)源码-zhizhu"提供了相关的Java源代码,供学习者和开发者参考,帮助他们理解网络爬虫的工作原理并进行...
- 2017-10-14 14:39Java网络爬虫可能需要处理这种情况,如使用Selenium WebDriver模拟浏览器执行JavaScript,或使用Headless Chrome/Firefox。 7. **反爬策略**: 避免被网站封禁是网络爬虫开发中的重要考虑。这包括设置合理的请求...
- 2022-07-15 11:11"amazon_爬"标签明确了该程序的目标平台是亚马逊网站,而"java爬虫"标签则表明程序使用的编程语言是Java,这在Java的网络爬虫开发中很常见,因为Java具有跨平台性、性能强和丰富的库支持等特点,适合处理复杂的网络...
- 没有解决我的问题, 去提问

