从oracle抽数据到hdfs报错,但是到最后还是执行成功。540万的数据,3.2G的数据,
请大神帮看下该如何解决,谢谢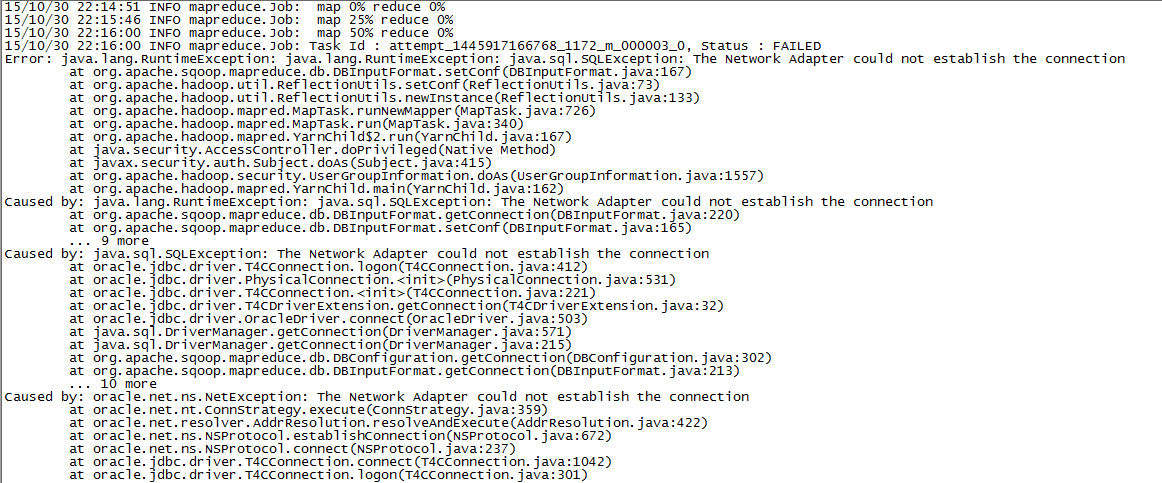

Sqoop从oracle抽取数据到hdfs

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
 你知我知皆知 2024-08-04 15:30关注
你知我知皆知 2024-08-04 15:30关注以下回答参考 皆我百晓生、券券喵儿 等免费微信小程序相关内容作答,并由本人整理回复。
首先,让我们确定问题的根本原因。根据您提供的错误信息和截图,我注意到有两个主要的问题:
- Oracle JDBC 驱动程序无法与网络适配器建立连接。
- 网络适配器可能无法正常工作。
为了修复这些问题,我们需要采取以下步骤:
-
检查Oracle JDBC驱动程序是否正确安装并启用。
- 打开命令提示符或终端(取决于您的操作系统)。
- 输入以下命令以检查Oracle JDBC驱动程序的版本:
javap -v - 如果驱动程序已过期,请尝试更新它。对于Windows系统,可以使用以下命令:
sudo apt-get install oracle-jdbc6
-
确保网络适配器正在运行且功能正常。
- 使用ping命令测试网络适配器是否能够正常工作。例如:
ping www.google.com
- 使用ping命令测试网络适配器是否能够正常工作。例如:
如果上述步骤不能解决问题,那么可能是数据库服务器端的问题。在这种情况下,您可以尝试联系Oracle支持团队获取进一步的帮助。
如果您有更详细的错误消息或日志文件,请提供给我,以便我可以为您提供更具体的解决方案。
解决 无用评论 打赏举报 分享