
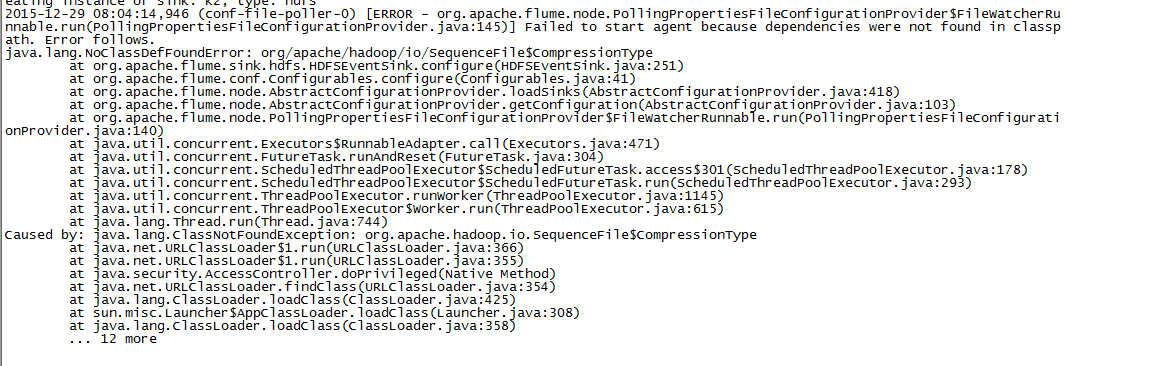
错误主要是这个:Failed to start agent because dependencies were not found in classpath.上图是报错,麻烦大神解决
下面是配置文件
#master_agent
master_agent.channels = c2
master_agent.sources = s2
master_agent.sinks = k2
#master_agent avrosources
master_agent.sources.s2.type = avro
master_agent.sources.s2.bind = master1
master_agent.sources.s2.port = 41415
master_agent.sources.s2.channels = c2
#master_agent filechannels
master_agent.channels.c2.type = file
master_agent.channels.c2.capacity = 100000
master_agent.channels.c2.transactionCapacity = 1000
#master_agent hdfssinks
master_agent.sinks.k2.type = hdfs
master_agent.sinks.k2.channel = c2
master_agent.sinks.k2.hdfs.path = hdfs://master1:9000/hdfs
master_agent.sinks.k2.hdfs.filePrefix = test-
master_agent.sinks.k2.hdfs.inUsePrefix = _
master_agent.sinks.k2.hdfs.inUseSuffix = .tmp
master_agent.sinks.k2.hdfs.fileType = DataStream
master_agent.sinks.k2.hdfs.writeFormat = Text
master_agent.sinks.k2.hdfs.batchSize = 1000
master_agent.sinks.k2.hdfs.callTimeout = 6000







