
我有一个表叫做sc.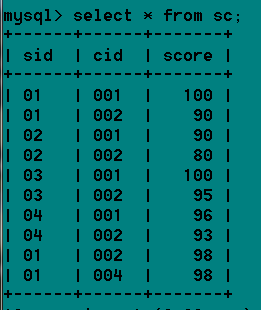
现在要查询score中有相同分数的信息,
查询的sql语句是
select * from sc where score in (select score from sc group by score having count(score)>1);
我很好奇的是group by的执行顺序是比 having先执行啊,
按道理,执行了之后重复的score值是没有的,怎么还能再用having 来查出count(score)>1
的重复的score记录啊...好奇怪..谁能解答下。。谢谢







