
用selenium模拟点击百度搜索结果链接, 已经用xpath正确定位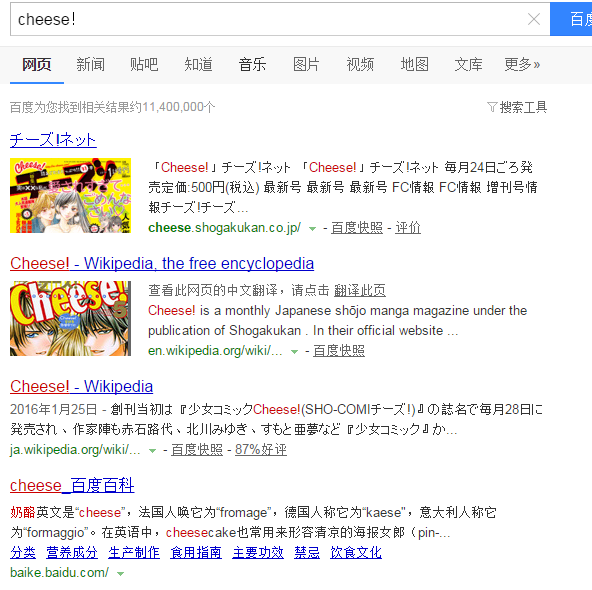
linb = driver.find_element_by_xpath("//div[@id='wrapper']/div[3]/div[1]/div[3]/div[4]/h3[1]/a")
linb.click()
如果结果标题是英文或日文可以正常点击,但带中文的话就会报错:
File "C:\Python27\lib\site-packages\selenium\webdriver\remote\webelement.py", line 75, in click
self._execute(Command.CLICK_ELEMENT)
File "C:\Python27\lib\site-packages\selenium\webdriver\remote\webelement.py", line 454, in _execute
return self._parent.execute(command, params)
File "C:\Python27\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 201, in execute
self.error_handler.check_response(response)
File "C:\Python27\lib\site-packages\selenium\webdriver\remote\errorhandler.py", line 107, in check_response
message = value["value"]["message"]
TypeError: string indices must be integers
求大神帮忙解答!谢谢!






