public int addTypes(List<taobaoBean> babyList) {
String sql = "insert into type (typeid,url) values (?,?) ";
Connection conn = dbhelper.getConnection(driver,url,username,upwd);
int result = 0;
PreparedStatement stmt =null;
try {
stmt = conn.prepareStatement(sql);
for(int i=0;i<babyList.size();i++){
stmt.setInt(1, babyList.get(i).getTypeId());
stmt.setString(2, babyList.get(i).getUrl());
stmt.addBatch();
}
stmt.executeBatch();
} catch (Exception e) {
e.printStackTrace();
}finally{
if (stmt != null) {
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
dbhelper.closeCon(conn);
}
return result;
}
1分钟才插入3000条数据,如何变快。

mysql 插入10万条数据 优化效率

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


4条回答 默认 最新

- 2022-06-07 18:49回答 1 已采纳 内部的每个括号,放的不是应该是一行的值么?你怎么放的一列?而且不要放主键
- 2018-05-14 14:01回答 19 已采纳 如是普通PC级服务器(或是更好一点的消费级服务器),你每条数据平均占用时间为40MS,考虑到你的每条数据有900多列。这样的话,已经不慢了。 如想更快的话: 1、查看是否有索引,索引是以降低插
- 2022-05-03 16:46回答 2 已采纳 举例:表A中有字段,设备id,name,设备数量num,日期date,取每个设备最早的10条数据。 select t.id,t.name from ( select t.id
- 2021-01-19 21:52MySQL创建存储过程批量插入10万条数据 存储过程 1、首先防止主键冲突,我们清空表。 TRUNCATE table A_student; 2、编写存储过程 delimiter ‘$’; CREATE PROCEDURE batchInsert(in args int) BEGIN declare i int ...
- 2022-03-31 17:24回答 5 已采纳 其实没有实际的标准明确定义多少数据量算大数据,不过阿里开发手册中建议,表数据超过500万条时,建议考虑分表,以防影响查询效率,不过我们公司也有单表超过几千万条的数据,效率确实不高,所以理论上百万级别以
- 2017-05-18 01:06回答 6 已采纳 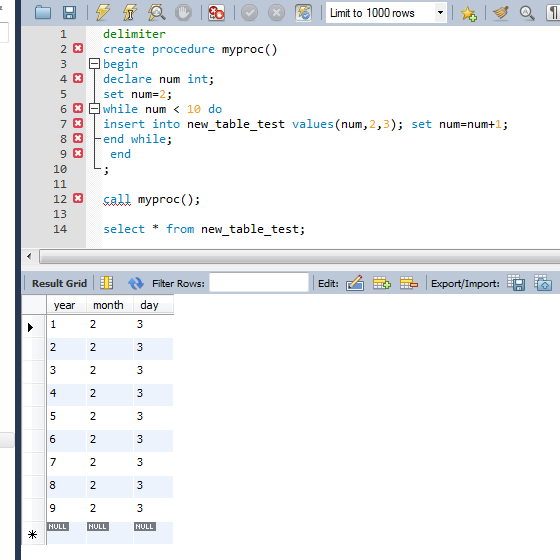 delimiter create proce
- 2017-11-09 03:01回答 3 已采纳 http://blog.csdn.net/panjican/article/details/52523410这个里面有相关讲解,看对你是否有帮助
- 2022-03-27 22:25code_____monkey的博客 这里第二种SQL执行效率高的主要原因是: (1)通过合并SQL语句,同时也能减少SQL语句解析的次数,减少了数据库连接的I/O开销,一般会把多条数据插入放在一条SQL语句中一次执行; (2)合并后日志量(MySQL的binlog和innodb...
- 2021-07-26 17:59回答 1 已采纳 在my.ini (在MySQL的安装目录下)文件中修改如下:把utf8 改为 gbk若没有生效,重启服务试试
- 2022-02-14 11:18回答 2 已采纳 你这个语法其实对于标准sql来说是个错的, 如果存在group by ,那么未聚合的字段必须都接在group by 后面,老版本的mysql没这个限制,但是查出来的数据是个随机的,比如你这个riqi,
- 2022-12-07 17:18回答 4 已采纳 使用 instr函数试试看 ,查询 like '%121%' select * from test t where instr(t.requestdata,'121')> 0;
- 2023-03-20 13:11共饮一杯无的博客 Java怎么实现几十万条数据插入(30万条数据插入仅需13秒)
- 2023-02-15 01:45回答 2 已采纳 因为character是mysql的保留字(关键字),如果需要使用保留字(关键字)当做字段名或表名时,则必须要在增删改查语句的字段名或表名中添加反引号,否则会造成字段名和保留字(关键字)冲突,从而引发
- 2021-02-02 14:02weixin_39996101的博客 1. 背景项目中有1000万条历史案卷,为某地方坐标系数据,我们的真实需求是将地方坐标系坐标反转成WGS84坐标,如果现在需要将其转换成百度坐标系数据。常规方案是先建立好整个该市的本地坐标和百度坐标之间的控制点库...
- 2020-07-09 21:46程序员闪充宝的博客 作者:在赤道吃冰棍儿www.jianshu.com/p/36b87cb3a05a前言假设现在我们要向mysql插入500万条数据,如何实现高效快速的插入进去?暂时不考虑数据的获取、网络I...
- 没有解决我的问题, 去提问



悬赏问题
- ¥100 求三轴之间相互配合画圆以及直线的算法
- ¥100 c语言,请帮蒟蒻写一个题的范例作参考
- ¥15 名为“Product”的列已属于此 DataTable
- ¥15 安卓adb backup备份应用数据失败
- ¥15 eclipse运行项目时遇到的问题
- ¥15 关于#c##的问题:最近需要用CAT工具Trados进行一些开发
- ¥15 南大pa1 小游戏没有界面,并且报了如下错误,尝试过换显卡驱动,但是好像不行
- ¥15 自己瞎改改,结果现在又运行不了了
- ¥15 链式存储应该如何解决
- ¥15 没有证书,nginx怎么反向代理到只能接受https的公网网站