如图,查询uid23所有count总数,怎么查呀
还有pid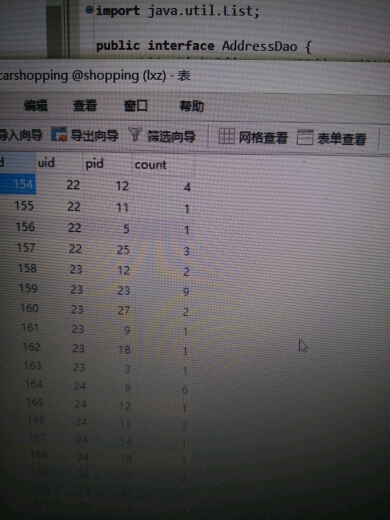

如图,查询uid23所有count总数,怎么查呀~

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新

- 2025-02-20 15:10德米安demian的博客 通过分离主表计数与关联查询的方案,我们既解决了分页总数统计错误的问题,又保证了关联数据的完整性。这种方案虽然需要多写一个计数查询,但在数据准确性和系统稳定性方面提供了更好的保障。对于不同的业务场景,...
- 2022-06-16 18:19clear_to_的博客 Elasticsearch 查询
- 2022-10-15 00:31- **独立UID总数**: 计算唯一用户ID(uuid)的数量。 - **查询频度排名**: 通过对查询词分组并计算频度,然后按降序排列,获取前50个最高频率的词。 - **查询次数不小于2次的顾客总数**: 统计查询次数超过2次的...
- 2025-09-01 19:59程序消消乐的博客 在真实的企业级大数据环境中,Hive 查询经常需要处理数百万甚至上亿条日志数据。复杂查询性能不足——、多层聚合、跨表 JOIN 等操作容易导致 Shuffle 数据量暴增,Reduce 阶段成为瓶颈。数据倾斜严重—— 部分热点...
- 2022-07-17 13:10光数葱丁的博客 本文主要介绍大数据相关的技术和项目目录1.1文章介绍介绍1.2项目介绍1.3 项目指标1.3.1离线指标1.3.2实时指标1.3.3最难的两个指标1.4项目遇到问题1.4.1 Sqoop1.4.2Flume1.4.3Kafka1.4.4Hadoop1.5 项目相关流程问题1....
- 2023-07-12 12:50Bigdata_shit的博客 1)DefaultPartitioner默认分区器 下图说明了默认分区器的分区分配策略: 2)UniformStickyPartitioner纯粹的粘性分区器 (1)如果指定了分区号,则会按照指定的分区号进行分配 (2)若没有指定分区好,则使用粘性...
- 2023-03-27 23:20daxina1978的博客 这是在学习大数据各种组件之后,开始系统的刷sql题和面试题的第十天!在牛客上选择SQL大厂面试真题系统刷题。
- 2017-05-19 11:54沉默王二的博客 uid=${mem.uid}" style= "width:400px" inputMessage= "请输入会员编号(可部分匹配)" > < option selected= "selected" value= "666" >沉默王二 option > select > Java端通过name属性可获得select的...
- 2025-05-31 22:30大熊计算机毕设的博客 本文深入讲解MySQL高级查询技巧,重点解析GROUP BY分组、HAVING过滤、聚合函数(COUNT/SUM/AVG等)及分页查询(LIMIT)的使用方法。内容涵盖多字段分组统计、子查询嵌套(SELECT/WHERE/FROM)、分页优化方案(覆盖...
- 2025-10-12 18:37辉哥大数据的博客 Spark用户自定义函数是一种功能强大的工具,它赋予...在Spark SQL中,用户自定义聚合函数(UDAF)允许用户实现复杂的聚合逻辑,这些逻辑不能通过Spark SQL的内置聚合函数(如sum()、avg()、max()、min()等)直接实现。
- 没有解决我的问题, 去提问

