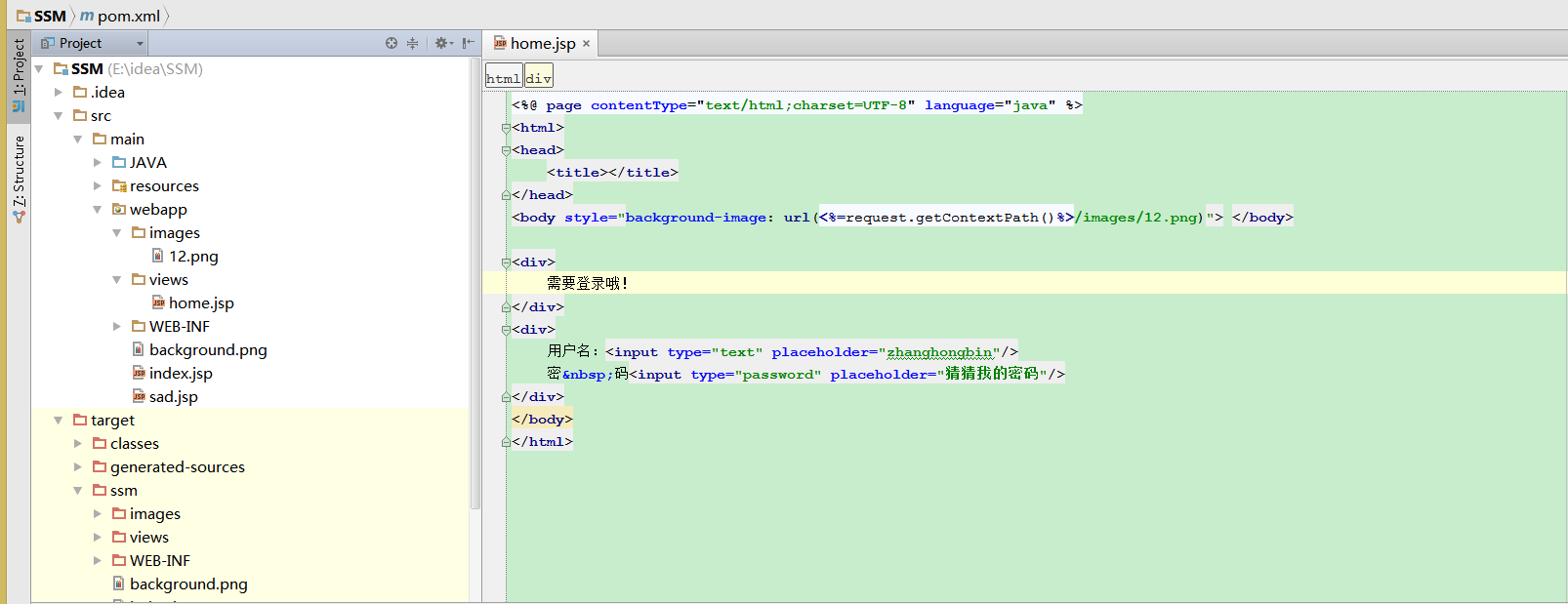
这是代码和项目结构图

jsp背景图片不能显示,求大神帮忙解答

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


5条回答 默认 最新

- 2021-06-01 16:56回答 6 已采纳 路径写错了,看看控制台的报错信息。
- 2022-05-14 00:10回答 2 已采纳 格式啊 老铁
- 2018-08-04 07:29回答 5 已采纳 已经解决:(原来是sql中含有字段不存在表中),谢谢大家!
- 2020-10-19 16:33okbin1991的博客 阿里四轮面试总结 第一轮面试电话(**5** 月 6 号): 1.自我介绍,包括做过项目。 2.有看过哪些 JDK 源码,了解哪些...5.classloader 结构,是否可以自己定义一个 java.lang.String 类,为什么? 双亲代理机制。 ...
- 2017-04-20 06:35回答 0 已采纳 . ./ 这个有问题,试着./../之类的调试一下。。。肯定可以的。。。 要不就jsp头部加上这路径 然后,所有地址前方都加上,类似下面 /design/css/.css" rel="sty
- 2017-12-29 02:59回答 15 已采纳 首先你这个思路就错误了,任何企业开发都不会把图片的二进制保存到数据库,图片太大,数据库会很快就满了,都是把图片保存到服务器的一个路径下, 例如tomcat的一个路径下面,然后把路径保存到数据库,这样
- 2022-03-19 13:42回答 2 已采纳 /1.jpg试下
- 2019-05-21 11:49A记录学习路线的博客 哈工大本硕985,北京公司,收到去哪儿(13K16),华为,vipkid(1814),茄子快传(2016),创新工厂(1213),秒针(1816)offer,目前最低的月薪12K13,最高的华为优招20K*16,最终还是签了百度毕竟bat,职位java开发...
- 2017-04-24 09:01回答 2 已采纳 在后台就应该将数据放好 这块应该写在后台 用bean封装起来 前台页面直接取值
- 2022-11-26 14:47回答 1 已采纳 你可以看下这个问题的回答https://ask.csdn.net/questions/7791137
- 2015-08-12 09:58回答 5 已采纳 用IE打开网页,按f12,打开调试面板,找到css,看下,你的图片路径到底是什么,对不对。
- 2016-05-23 09:53小扁加油的博客 , 请教hibernate排序问题, java 权限管理, 如何实现在jsp页面中选择txt文件,点击下载时进行下载, 帮忙注释下面代码,谢谢, HIBERNATE HQL查询问题请教, 第一次发帖,求各位大神帮忙解决个tomcat问题。, 大家帮忙看...
- 2022-04-20 14:09回答 3 已采纳 使用utf-16
- 2016-09-13 17:26Eastmount的博客 两年前,我本科毕业写了这样一篇文章:《回忆自己的大学四年得与失》,感慨了自己在北理软院四年的所得所失;...文章可能有点长,但希望大家像读小说一样耐心品读,看完之后也能温馨一笑或唏嘘摇头...
- 2014-11-07 13:05Ravenq~的博客 对于咱们这些高端大气、...否则,试想在你捧着某出版社刚刚翻译出来的《JSP 高效编程》苦苦学习JSP模板的时候,你旁边的小弟却是拿着原版的《AngularJS in Action》学习开发单页面应用,虽然你们都同样认真地学习了一
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 安卓adb backup备份应用数据失败
- ¥15 eclipse运行项目时遇到的问题
- ¥15 关于#c##的问题:最近需要用CAT工具Trados进行一些开发
- ¥15 南大pa1 小游戏没有界面,并且报了如下错误,尝试过换显卡驱动,但是好像不行
- ¥15 没有证书,nginx怎么反向代理到只能接受https的公网网站
- ¥50 成都蓉城足球俱乐部小程序抢票
- ¥15 yolov7训练自己的数据集
- ¥15 esp8266与51单片机连接问题(标签-单片机|关键词-串口)(相关搜索:51单片机|单片机|测试代码)
- ¥15 电力市场出清matlab yalmip kkt 双层优化问题
- ¥30 ros小车路径规划实现不了,如何解决?(操作系统-ubuntu)