在APUE书中看到图显示:i节点是在磁盘上的。在《linux内核设计与实现 第3版》中说:索引节点仅当文件被访问时,才在内存中创建。
请问:inode到底是在磁盘上,还是在内存中? 另外,图中是否每个分区对应于某个系统目录(比如/usr分区 /home分区 /dev分区等等)
附注:
1 下面的这个图是来自《APUE 第3版》4-13节: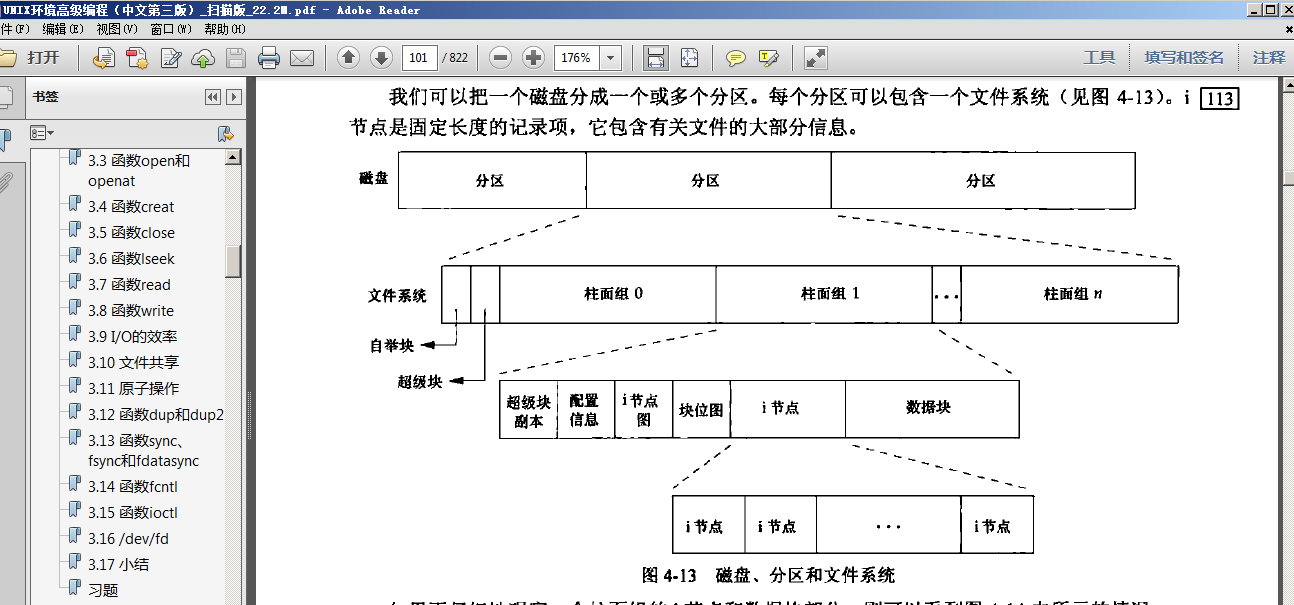
2 下面的这个截图是来自《linux内核设计与实现 第3版》13.7节

在APUE书中看到图显示:i节点是在磁盘上的。在《linux内核设计与实现 第3版》中说:索引节点仅当文件被访问时,才在内存中创建。
请问:inode到底是在磁盘上,还是在内存中? 另外,图中是否每个分区对应于某个系统目录(比如/usr分区 /home分区 /dev分区等等)
附注:
1 下面的这个图是来自《APUE 第3版》4-13节:
2 下面的这个截图是来自《linux内核设计与实现 第3版》13.7节
 分享
分享
硬盘上会存放,但系统会加载到内存来提升性能。
inode也会消耗硬盘空间,所以硬盘格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个是inode区(inode table),存放inode所包含的信息。
每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode。假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
分享


