请大神帮忙解决一下:六台机器,SparkStreaming的例子程序,运行在yarn上四个计算节点(nodemanager),每台8G内存,i7处理器,想测测性能。
自己写了socket一直向一个端口发送数据,spark 接收并处理
运行十几分钟汇报错:WARN scheduler TaskSetManagerost task 0.1 in stage 265.0 :java.lang.Exception:Could not compute split ,block input-0-145887651600 not found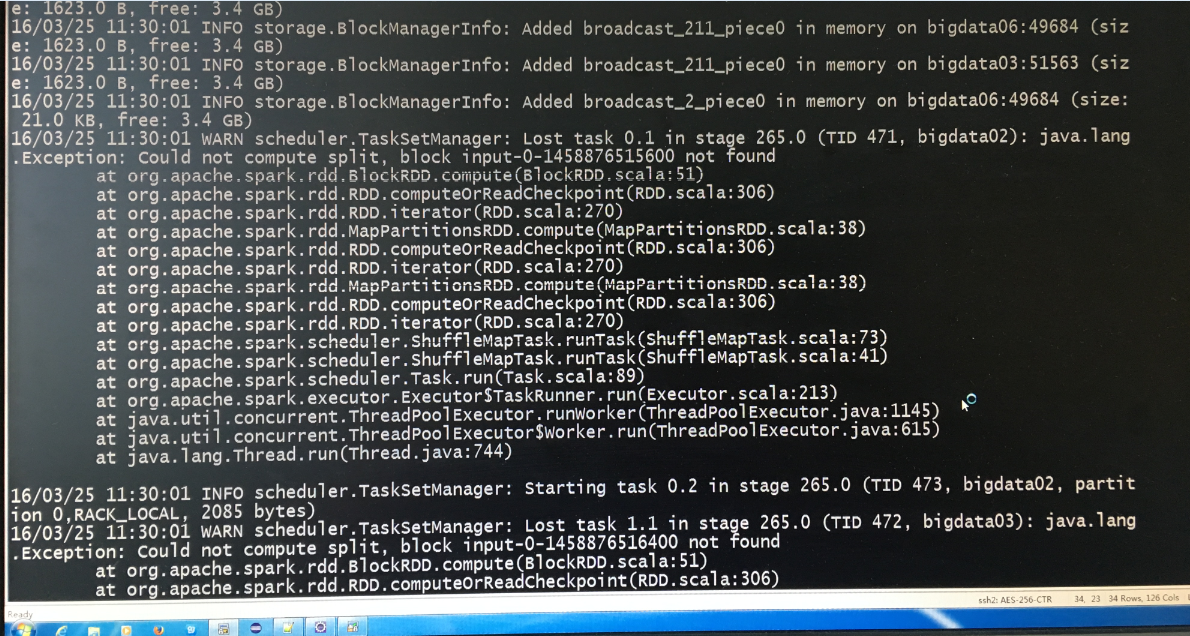

六台机器集群,40M数据就报错,spark streaming运行例子程序wordcount

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

0条回答 默认 最新
- 2024-10-21 10:00Francek Chen的博客 智能大数据分析实验四,Spark实验:Spark Streaming。理解Spark Streaming的工作流程和工作原理,将Spark Streaming集群与Kafka集群对接,通过Java编程代码导出jar包并运行,实现SparkStreaming实时流处理。
- 2022-03-27 15:08技匠三石弟弟的博客 从TCP Socket数据源实时消费数据,对每批次Batch数据进行词频统计WordCount,流程图如下: 二、准备工作 本地使用nc命令,利用它向8888端口发送数据(备注:nc是netcat的简称,原本是设置路由器),输入命令如下...
- 2018-09-13 20:57桃花惜春风的博客 关于Spark-Streaming官方示例: https://github.com/apache/spark/tree/master/examples 本文采用kafka作为spark输入源 运行时出现以下日志: 18/09/12 11:15:28 INFO JobScheduler: Added jobs ...
- 2021-11-15 13:41似懂非dong的博客 启动sparkStreaming中案例中的客户端程序, 通过nc监听服务器发送的数据,对数据进行词频统计。实现sparkStreaming流式处 理的wordcount入门程序 三、官网案例 1、启动nc nc -l -p 6666 2、启动sparkStreaminga案例...
- 2021-12-15 11:00好好踢球啦的博客 Spark Streaming 用于流式数据的处理。Spark Streaming 支持的数据输入源很多,例如:Kafka、 Flume、Twitter、ZeroMQ 和简单的 TCP 套接字等等。数据输入后可以用 Spark 的高度抽象原语 如:map、reduce、join、...
- 2022-02-15 21:29看见我的小熊没的博客 SparkStreaming中的数据抽象叫做DStream。DStream是抽象类,它把连续的数据流拆成很多的小RDD数据块, 这叫做“微批次”, spark的流式处理, 都是“微批次处理”。 DStream内部实现上有批次处理时间间隔,滑动...
- 2022-07-05 10:13不懂开发的程序猿的博客 掌握IntelliJ Idea创建Spark...Spark Streaming内部的基本工作原理如下:接收实时输入数据流,然后将数据拆分成多个batch,比如每收集1秒的数据封装为一个batch,然后将每个batch交给Spark的计算引擎进行处理,最后会生
- 2020-10-23 17:29我玩的很开心的博客 Spark Streaming 实现 word count一、一个输入源端口对应一个receiver1.1 数据源端口1.2 spark streaming 接收处理数据二、两个输入源端口对应一个receiver2.1 测试源端口 一、一个输入源端口对应一个receiver 1.1 ...
- 2022-05-24 22:02简单的小呆瓜的博客 mkdir -p streaming/logfile 1.2 进入spark-shell cd cd spark-3.1.1-bin-hadoop2.7/bin/ spark-shell 1.3 命令行依次输入以下代码查看实验结果 import org.apache.spark._ import org.apache.spark...
- 2020-05-21 15:24布莱恩特888的博客 SparkStreaming入门+WordCount案例1. Spark Streaming概述1.1 离线和实时的概念1.2 批量和流式的概念1.3 Spark Streaming是什么1.4 Spark Streaming特点1.5 Spark Streaming架构2. DStream入门2.1 WordCount案例实操...
- 没有解决我的问题, 去提问
